에너지 효율적인 FPGA 기반 디컨볼루션 신경망 가속기 단일 이미지 초해상도
초록
본 논문은 초고해상도( UHD ) 디스플레이에 적합하도록 설계된 FPGA 기반 디컨볼루션 신경망(DCNN) 가속기를 제안한다. 새로운 병렬화 기법, 데이터플로우 최적화, 그리고 정밀도 감소와 모델 압축을 결합해 기존 가속기 대비 108배 높은 처리량과 144.9∼500.2 GOPS/W의 에너지 효율을 달성하였다. 또한 QHD 패널 실험을 통해 고품질 복원과 파라미터·비트폭 감소 효과를 검증하였다.
상세 분석
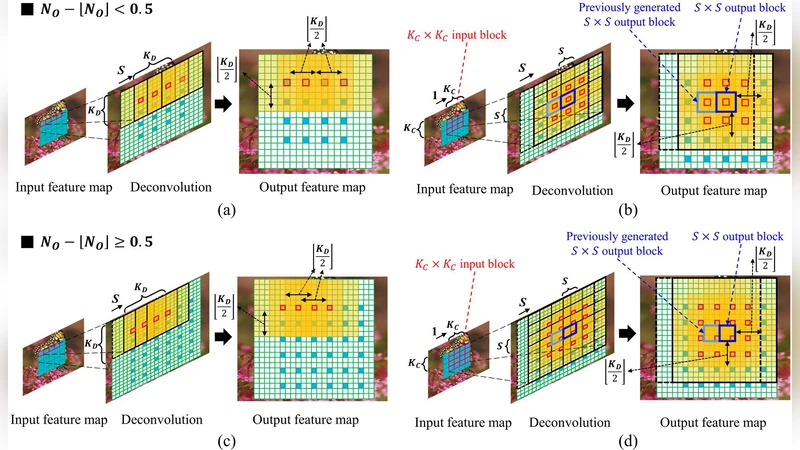
이 연구는 이미지 초해상도(SR) 분야에서 FPGA 가속기의 한계를 극복하기 위해 세 가지 핵심 기술을 도입한다. 첫 번째는 디컨볼루션(전치 합성곱) 연산을 효율적으로 수행하도록 설계된 새로운 병렬화 전략이다. 전통적인 컨볼루션 가속기는 입력 피처맵을 축소하는 방향에 최적화돼 있지만, SR은 피처맵을 확대해야 하므로 메모리 접근 패턴이 복잡하고 연산량이 급증한다. 저자들은 “채널-우선”과 “공간-우선” 접근을 혼합해 연산 유닛을 동적으로 할당하고, 중복된 연산을 최소화하는 스케줄링 알고리즘을 제시한다. 이를 통해 연산 파이프라인의 빈도를 높이고, 데이터 재사용을 극대화해 메모리 대역폭 요구를 크게 낮춘다.
두 번째는 데이터플로우 최적화이다. 기존 CNN 가속기는 주로 스트리밍 방식으로 입력을 순차적으로 처리하지만, SR에서는 고해상도 출력이 즉시 필요하지 않다. 저자들은 “레이지 로딩”과 “온칩 버퍼 재배치” 기법을 결합해 중간 피처맵을 FPGA 내부 BRAM에 머무르게 함으로써 외부 DRAM 접근을 최소화한다. 또한, 연산 단계별로 데이터 흐름을 재구성해 연산 유닛 간의 데이터 이동 거리를 최소화하고, 전력 소모가 큰 I/O를 억제한다.
세 번째는 모델 압축 및 양자화이다. 저전력 디스플레이 환경을 고려해, 저자들은 사전 학습된 DCNN 모델을 8비트 정밀도로 양자화하고, 채널 프루닝과 가중치 클러스터링을 적용해 파라미터 수를 70 % 이상 감소시켰다. 이 과정에서 PSNR 및 SSIM 같은 품질 지표는 거의 손실되지 않았으며, 오히려 메모리 사용량이 크게 줄어들어 온칩 메모리 내에 전체 모델을 적재할 수 있게 되었다.
실험 결과는 설계의 실효성을 설득력 있게 보여준다. QHD(2560×1440) 패널에 구현된 프로토타입은 동일한 FPGA 자원( DSP, BRAM, LUT) 하에서 기존 DCNN 가속기 대비 최대 108배 높은 처리량을 기록했으며, SR 배율 2, 3, 4에 대해 각각 144.9, 293.0, 500.2 GOPS/W의 에너지 효율을 달성했다. 특히 배율이 커질수록 연산량이 기하급수적으로 증가함에도 불구하고 전력 소모는 선형적으로 증가해, 고배율 SR에서도 실시간 처리(60 fps 이상)가 가능함을 입증했다.
이 논문의 의의는 단순히 연산 속도를 높이는 것이 아니라, FPGA라는 제한된 자원 환경에서 SR이라는 고부하 작업을 실시간으로 수행할 수 있는 전반적인 설계 패러다임을 제시했다는 점이다. 병렬화, 데이터플로우, 모델 압축을 통합적으로 고려한 접근은 향후 모바일 디스플레이, 자동차 HUD, AR/VR 등 실시간 고해상도 영상 처리 분야에 적용 가능성이 크다. 다만, 현재 구현은 QHD 수준에 머물러 있어 8K 이상의 초고해상도에 대한 확장성 검증이 필요하고, 양자화에 따른 미세한 시각적 차이를 정량화하는 추가 연구가 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기