전자건강기록을 위한 의미단어순서 벡터화 기법
초록
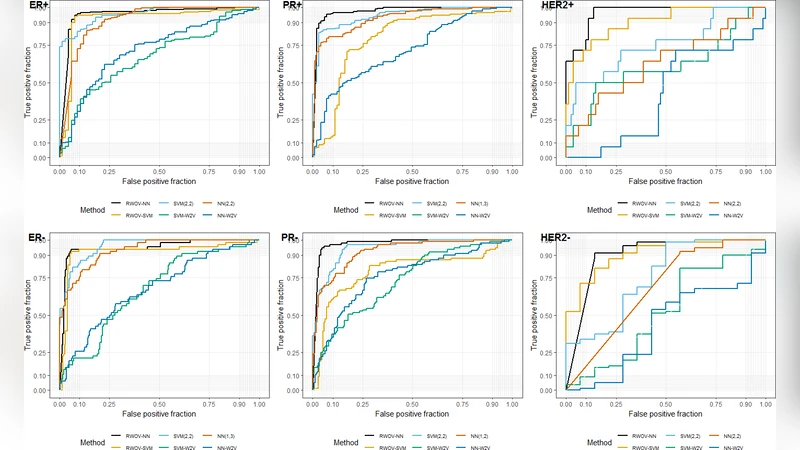
본 논문은 전자건강기록(EHR) 텍스트에서 핵심 용어와 그 순서를 활용한 새로운 벡터화 방법인 Relevant Word Order Vectorization(RWOV)을 제안한다. 유방암 병리보고서의 호르몬 수용체 상태(ER, PR, HER2)를 분류하는 실험에서 RWOV은 n‑gram 및 word2vec 기반 모델보다 F1 점수와 AUC에서 일관되게 우수한 성능을 보였다.
상세 분석
RWOV은 “관심 용어(TOI)”를 중심으로 가장 빈번히 동반되는 단어들을 ‘top words’로 선정하고, 각 문서에서 TOI와 top word 사이의 거리와 순서를 정량화한다. 구체적으로, 문서‑단위 행렬을 구성해 행은 환자, 열은 top word를 나타내며 셀 값은 TOI와 해당 단어 사이에 존재하는 top word 개수의 역수(±부호)로 채워진다. 이 방식은 0에서 1 사이의 비선형 감소를 자연스럽게 구현해, TOI에 가까울수록 큰 가중치를 부여한다. 기존 n‑gram은 고정된 n 범위 내의 연속 토큰을 카운트하고, word2vec은 주변 단어를 예측하는 방식으로 의미를 학습하지만, 두 방법 모두 텍스트 내 위치 정보를 충분히 활용하지 못한다. RWOV은 EHR 특유의 반구조적 서술—예를 들어 “ER positive, PR negative”와 같이 키워드가 반복되고 순서가 의미를 결정하는 경우—에 최적화돼 있다. 실험에서는 top word 수 하나만을 하이퍼파라미터로 두고, 동일한 학습·검증 분할을 사용해 SVM과 인공신경망(NN) 두 분류기에 적용했다. 결과는 특히 HER2 양성(14건)과 같이 소수 클래스에서 RWOV‑NN이 F1 0.71, AUC 0.96을 기록하며 기존 방법을 크게 앞섰다. 이는 거리‑가중치가 희소한 신호를 증폭시켜 소수 클래스 판별력을 높인 것으로 해석된다. 그러나 데이터가 한 기관·한 연도에 국한되고, 토큰 전처리(스테밍·불용어 제거)만을 적용했으며, top word 선정이 빈도 기반이라 동의어·약어 처리에 한계가 있다. 또한, 거리 기반 가중치가 문맥적 의미(예: 부정어 “not”)를 충분히 반영하지 못할 가능성도 존재한다. 향후 다기관·다언어 데이터셋, 동적 top word 선택, 부정어 처리 등을 결합하면 일반화 성능을 더욱 향상시킬 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기