데이터 프로그래밍 대규모 학습 데이터셋을 빠르게 만들기
데이터 프로그래밍은 도메인 전문가가 약한 감독 전략을 라벨링 함수 형태로 코딩하고, 이를 생성 모델로 정형화해 노이즈를 추정·제거함으로써 대량의 라벨링 데이터를 자동 생성한다. 학습 단계에서는 이 추정된 라벨 분포를 이용해 노이즈‑인식 손실을 최소화하고, 실험에서는 슬롯‑필링 및 LSTM 모델에서 기존 지도 학습 대비 크게 향상된 F1 점수를 기록했다.
저자: Alex, er Ratner, Christopher De Sa
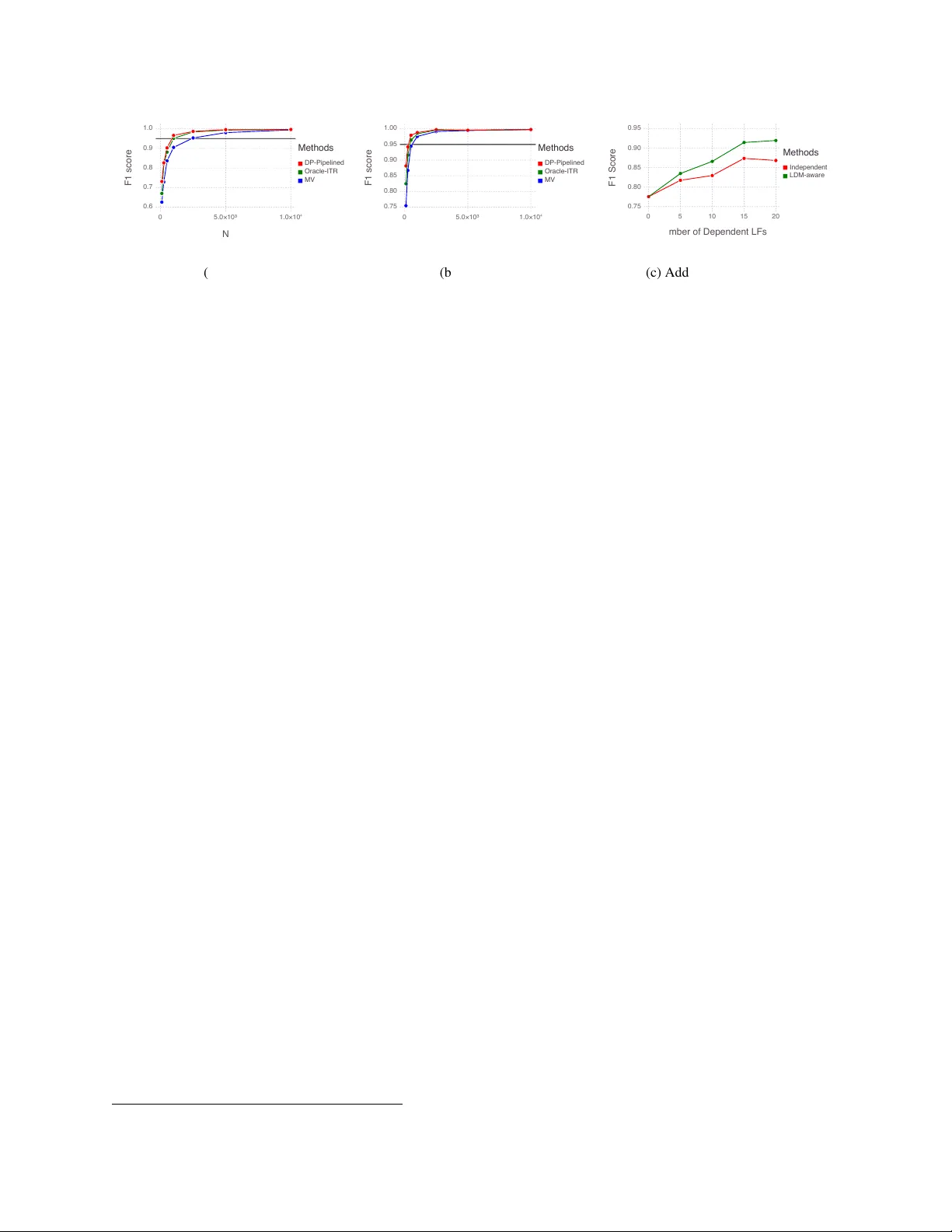
이 논문은 대규모 지도 학습에 필수적인 라벨링 데이터 확보 비용을 낮추기 위해 ‘데이터 프로그래밍(Data Programming)’이라는 새로운 약한 감독 패러다임을 제안한다. 데이터 프로그래밍에서는 도메인 전문가가 라벨링 함수를 작성한다. 라벨링 함수 λ_i는 입력 x에 대해 –1, 0, 1 중 하나를 반환하며, 0은 해당 함수가 라벨을 제공하지 않음을 의미한다. 이러한 함수들은 기존의 지식베이스 매핑, 정규표현식 기반 패턴, 혹은 휴리스틱 결합 등 다양한 형태를 가질 수 있다. 라벨링 함수들은 서로 겹치거나 충돌할 수 있으며, 정확도와 커버리지가 서로 다르다.
첫 번째 핵심 단계는 라벨링 함수들의 출력을 생성 모델로 정형화하는 것이다. 가장 단순한 경우, 각 함수는 실제 라벨 Y에 대해 독립적으로 동작한다는 가정 하에, 라벨을 출력할 확률 β_i와 정확도 α_i를 파라미터화한다. 이때 관측된 라벨링 결과 Λ와 잠재 라벨 Y의 결합 확률 µ_{α,β}(Λ, Y)를 정의하고, 비지도 데이터 S에 대해 로그우도를 최대화함으로써 (α̂, β̂)를 추정한다. 논문은 이 과정이 SGD로 효율적으로 해결될 수 있음을 보이며, 파라미터 추정이 충분히 정확하면 이후 단계에서 라벨링 노이즈를 보정할 수 있음을 증명한다.
두 번째 단계는 추정된 생성 모델을 이용해 ‘노이즈‑인식’ 손실 함수를 구성하는 것이다. 라벨링 함수가 제공한 Λ와 추정된 파라미터를 조건부 확률 분포로 사용해, 잠재 라벨 Y에 대한 로그‑손실의 기대값을 계산한다. 이 기대 손실은 실제 라벨이 없더라도 라벨링 함수들의 출력만으로 정의될 수 있다. 따라서 판별 모델 w (예: 로지스틱 회귀, LSTM 등)는 L_{α̂,β̂}(w;S)= (1/|S|)∑_{x∈S} E_{Y∼µ_{α̂,β̂}}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기