네트워크 연결 로그 이상 탐지
초록
본 논문은 ELK, Spark, Hadoop 기반의 스트리밍 파이프라인을 구축하여 CERN 데이터베이스 연결 로그를 실시간으로 수집·저장·분석하고, 라벨이 없는 로그에 대해 비지도 학습 기반 클러스터링·밀도·분류 알고리즘을 적용해 이상치를 탐지한다. 파라미터 최적화와 시각화를 통해 모델별 차이를 비교하고, 실제 보안 이벤트와 연계해 검증한다.
상세 분석
이 연구는 대규모 과학 인프라에서 발생하는 초당 수백 건의 연결 로그를 처리하기 위해 ELK(Stack: Elasticsearch, Logstash, Kibana)와 Apache Kafka, Flume을 이용한 데이터 수집·버퍼링·단기·장기 저장 구조를 설계하였다. 단기 저장은 Elasticsearch에, 장기 저장은 HDFS에 Parquet 포맷으로 저장함으로써 압축 효율과 쿼리 성능을 동시에 확보한다. 데이터 파이프라인의 성능 평가는 Flume‑Kafka, Parquet‑Avro 두 축으로 이루어졌으며, Kafka 기반이 높은 처리량과 낮은 지연을 보였고, Parquet이 스캔 성능에서 Avro를 앞섰다.
로그 전처리 단계에서는 연결 요청 시각, 사용자 ID, 데이터베이스 인스턴스, 요청 유형 등 30여 개 필드를 추출하고, 고차원 특성 공간을 PCA와 SVD로 2~3 차원으로 축소한다. 차원 축소는 노이즈 감소와 시각화 목적뿐 아니라, 이후 적용되는 비지도 학습 알고리즘의 계산 복잡도를 크게 낮춘다.
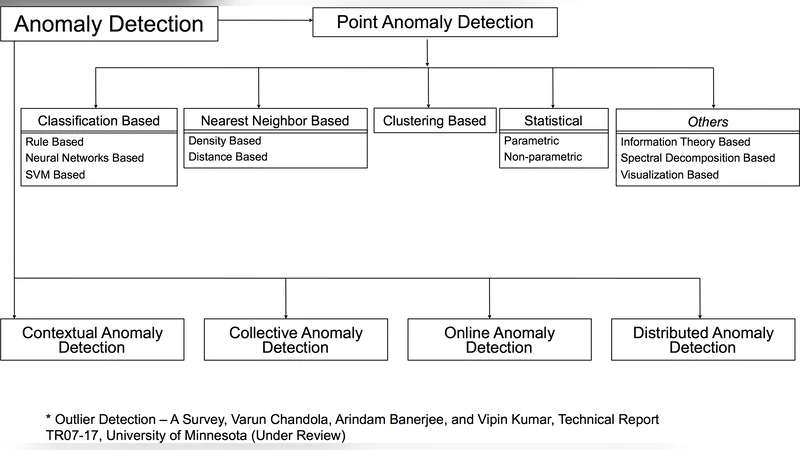
비지도 탐지 모델은 크게 거리 기반(k‑Nearest Neighbors), 밀도 기반(Isolation Forest, Local Outlier Factor), 그리고 경계 기반(One‑Class SVM)으로 구분된다. 각 모델은 “contamination” 파라미터를 2~5% 범위에서 조정했으며, 실험 결과 실시간 스트리밍 환경에서 Isolation Forest가 가장 낮은 연산 복잡도와 높은 검출률을 보였다. 그러나 LOF는 지역 밀도 변화를 민감하게 포착해 특정 사용자 패턴 변동을 잘 드러냈고, OCSVM은 커널 선택에 따라 경계 형태를 유연하게 조정할 수 있었다.
모델 평가에는 라벨이 없으므로 전통적인 정확도·재현율 대신 실루엣 점수와 인간 전문가의 보안 사건 매칭을 활용했다. 실루엣 평균 0.35를 초과한 모델은 군집 구조가 비교적 명확함을 의미했으며, 실제 보안 로그와 교차 검증한 결과 악성 스크립트에 의한 재연결, 비정상적인 휴일 로그인, 비정상적인 다중 자원 요청 등 세 가지 유형의 이상 행동을 성공적으로 포착했다.
전체 시스템은 스케일 아웃이 용이하도록 컨테이너화된 마이크로서비스 형태로 구현되었으며, Kafka 토픽 수와 Spark 스트리밍 배치 크기 등을 동적으로 조정함으로써 수천 대의 데이터베이스와 수백 GB/초 로그 흐름을 안정적으로 처리한다. 연구는 CERN 환경에 특화되었지만, 데이터 레이크와 스트리밍 기반 비지도 이상 탐지 파이프라인을 다른 대규모 IT 인프라에 그대로 적용할 수 있음을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기