고속도로 LSTM RNN을 이용한 원거리 음성 인식
본 논문은 기존 깊은 LSTM 구조에 인접 층 메모리 셀을 직접 연결하는 ‘하이웨이’ 게이트를 도입하고, 지연 제어 양방향 LSTM(L C‑BLSTM)을 설계하여 원거리 마이크 환경(AMI SDM)에서의 인식 정확도를 크게 향상시켰다. 하이웨이 LSTM은 층간 정보 흐름을 원활하게 하여 기울기 소실을 완화하고, 더 깊은 네트워크 학습을 가능하게 한다. 또한 프레임‑레벨 및 시퀀스‑레벨 손실 함수 모두에 효율적인 학습 알고리즘을 제시한다. 실험 …
저자: Yu Zhang, Guoguo Chen, Dong Yu
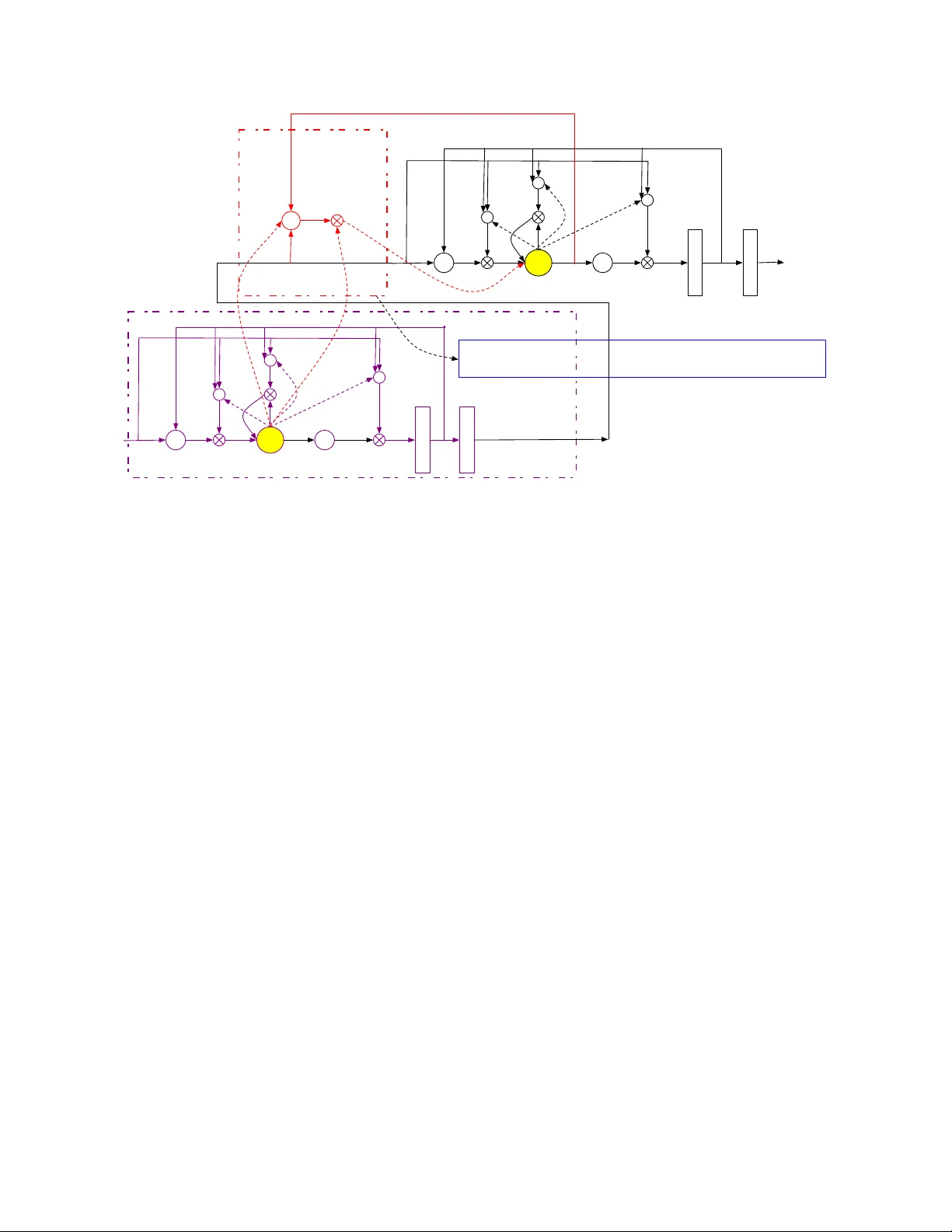
본 논문은 원거리 음성 인식(DSR) 분야에서 딥러닝 기반 음향 모델의 한계를 극복하기 위해 두 가지 새로운 RNN 구조와 학습 기법을 제안한다. 첫 번째는 ‘하이웨이 LSTM(HLSTM)’이라 불리는 구조로, 기존 깊은 LSTM(Deep LSTM, DLSTM)에서 층간 연결이 오직 출력‑입력 형태로만 이루어지는 문제를 해결한다. 저자들은 인접 층의 메모리 셀(c_l t)과 상위 층의 메모리 셀(c_{l+1} t) 사이에 게이트화된 직접 연결(d_{l+1} t)을 삽입한다. 이 ‘carry gate’는 현재 입력, 이전 셀 상태, 그리고 하위 층 셀 상태를 모두 고려해 sigmoid 형태로 활성화된다. 수식적으로는
d_{l+1} t = σ(b_d^{l+1} + W_{xd}^{l+1} x_{l+1} t + w_{cd}^{l+1} ⊙ c_{l+1} t‑1 + w_{ld}^{l+1} ⊙ c_l t)
이며, 최종 셀 상태는
c_{l+1} t = d_{l+1} t ⊙ c_l t + f_{l+1} t ⊙ c_{l+1} t‑1 + i_{l+1} t ⊙ tanh(·).
이 구조는 d_{l+1} t가 1에 가까울 경우 하위 층의 셀 상태가 거의 그대로 전달되어 ‘고속도로’처럼 층간 정보를 흐르게 하고, 0에 가까우면 전통적인 LSTM 연산이 우세하게 된다. 따라서 학습 초기에 셀 간 직접 전달을 강화해 기울기 소실을 방지하고, 깊은 네트워크(8층 이상)에서도 안정적인 수렴이 가능해진다.
두 번째 제안은 ‘지연 제어 양방향 LSTM(LC‑BLSTM)’이다. 표준 BLSTM은 전체 발화가 끝날 때까지 미래 정보를 모두 필요로 하므로 실시간 시스템에 부적합하다. LC‑BLSTM은 과거 히스토리를 무제한으로 유지하면서, 미래 컨텍스트는 고정된 프레임 수(N_r)만큼만 미리 보는 방식으로 지연을 제한한다. 구현은 입력 시퀀스를 길이 N_c인 청크로 나누고, 각 청크 앞에 N_l 프레임의 과거 컨텍스트를 이전 청크에서 그대로 이어받는다. 이렇게 하면 청크 간 중복 연산이 사라지고, 실제 지연은 N_r 프레임으로 정확히 제어된다. 실험에서는 N_c=22, N_r=21을 사용했으며, 40개의 발화를 동시에 처리해 기존 CSC‑BPTT 대비 1.5배 빠른 학습 속도를 달성했다.
학습 효율을 높이기 위해 두 번의 전방 패스를 이용한 시퀀스 레벨 손실 계산 방식을 도입했다. 첫 번째 전방 패스에서는 미니배치 내 여러 청크의 로그우도만 수집하고 모델 파라미터는 업데이트하지 않는다. 충분한 로그우도가 모이면 역전파를 수행하기 위해 두 번째 전방 패스로 전환한다. 이 방법은 한 번에 더 많은 시퀀스를 미니배치에 포함시켜 GPU 메모리 활용도를 극대화하고, 전체 학습 시간을 크게 단축한다.
또한 하이웨이 연결에 드롭아웃을 적용해 연결 강도를 조절한다. 초기 학습 단계에서는 낮은 드롭아웃(0.1)으로 연결을 활성화하고, 5 epoch 이후에는 높은 드롭아웃(0.8)으로 불필요한 연결을 억제한다. 이는 과적합을 방지하고 일반화 성능을 향상시키는 데 핵심적인 역할을 한다.
실험은 AMI 회의 코퍼스의 단일 원거리 마이크(SDM) 설정을 사용했다. 전체 80시간 훈련 데이터와 9시간씩의 dev, eval 세트를 활용했으며, NIST asclite로 WER을 측정했다. 기본 DNN(6층, 2048 유닛) 모델은 dev/eval에서 각각 57.5 %/48.4 %의 WER을 기록했다. 3층 LSTMP는 50.7 %/41.7 %였으며, 동일 구조에 하이웨이 연결을 추가한 HLSTMP는 50.4 %/41.2 %로 소폭 개선되었다. 그러나 하이웨이 연결에 드롭아웃을 적용한 BHLSTMP는 47.5 %/37.9 %로 가장 큰 향상을 보였다. 양방향 모델에서도 비슷한 경향이 나타났으며, LC‑BLSTM 기반 BHLSTMP는 최종적으로 dev/eval에서 43.9 %/47.7 % WER을 달성, 기존 최고 기록을 넘어섰다.
요약하면, 하이웨이 게이트는 깊은 LSTM 네트워크에서 층간 정보 흐름을 직접적이고 가변적으로 만들어 기울기 소실을 완화하고, LC‑BLSTM은 실시간 제약을 만족하면서도 양방향 컨텍스트의 이점을 유지한다. 두 기술을 결합하고 효율적인 학습 파이프라인을 적용함으로써 원거리 음성 인식에서 현존하는 최고 성능을 달성했으며, 제안된 구조와 학습 방법은 다른 시계열 처리 작업에도 일반화 가능성이 높다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기