딥 CNN과 이상적인 이진 마스크·교차 엔트로피를 이용한 보컬 분리 기술
초록
본 논문은 음악 혼합 신호에서 보컬을 분리하기 위해, 이미지 분할에서 영감을 받은 픽셀‑와이즈 분류 방식을 적용한 심층 합성곱 신경망(CNN)을 제안한다. 목표 라벨로 이상적인 이진 마스크(IBM)를 사용하고, 손실 함수는 교차 엔트로피를 채택한다. 또한 보컬 스펙트로그램을 이용해 자동인코더 사전학습을 수행한다. iKala와 DSD100 데이터셋에서 기존 최고 성능 모델들을 능가하거나 동등한 결과를 얻으며, 후처리 단계인 Wiener 필터를 제거할 수 있다.
상세 분석
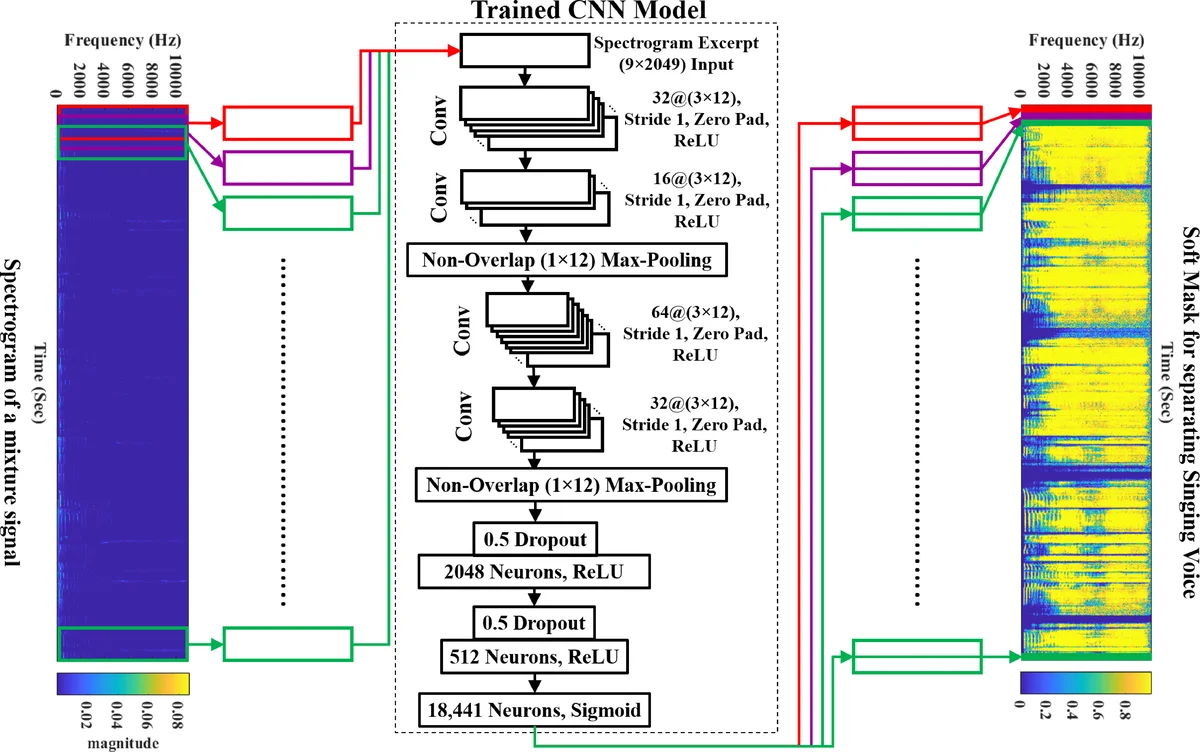
이 논문은 보컬‑반주 분리 문제를 시각 분야의 픽셀‑와이즈 이미지 분류와 동일시함으로써, 시간‑주파수(T‑F) 영역의 각 셀을 ‘픽셀’로 간주한다. 이를 위해 먼저 혼합 신호에 STFT를 적용해 magnitude spectrogram X와 phase pX를 얻고, 9프레임(≈104 ms) 길이의 스펙트로그램 슬라이스(9 × 2049)를 CNN의 입력으로 사용한다. 핵심 아이디어는 이상적인 이진 마스크(IBM)를 목표 라벨로 삼는 것이다. IBM은 각 T‑F 셀에서 보컬 에너지가 반주 에너지보다 클 경우 1, 그렇지 않으면 0으로 정의되며, 이는 다중 라벨 분류 문제로 변환된다. 손실 함수로는 교차 엔트로피를 채택해, 예측 확률 분포와 IBM 사이의 평균 KL divergence을 최소화한다. 이는 기존의 L2‑loss 기반 스펙트럼 재구성보다 라벨링 오류에 더 민감하게 반응하여, 소스‑특정 마스크 학습에 유리하다.
네트워크 구조는 초기 레이어를 자동인코더 방식으로 사전학습한다. 보컬 전용 스펙트로그램을 입력으로 하여, 인코더‑디코더가 보컬 특성을 압축·복원하도록 훈련함으로써, 이후의 분류 CNN이 보컬 특성을 보다 효과적으로 추출하도록 초기 가중치를 제공한다. 본 논문에서 제안한 CNN은 VGG‑계열의 작은 변형으로, 2~3개의 convolution‑pooling 블록 뒤에 1×1 convolution을 두어 각 픽셀에 대한 클래스 확률을 직접 출력한다. 마지막 sigmoid 활성화는 각 셀에 대한 보컬 존재 확률을 제공하고, 이를 바로 soft mask로 활용한다. 따라서 전통적인 Wiener 필터와 같은 후처리 단계가 불필요해진다.
학습에는 iKala(76 분)와 DSD100(216 분) 두 데이터셋을 활용했으며, 데이터 양이 제한된 상황에서도 좋은 일반화 성능을 보였다. 평가 지표인 GNSDR에서 iKala에 대해 기존 최고 모델 대비 2.27 ~ 5.96 dB 향상을 기록했으며, DSD100 전체 트랙 평가에서도 최신 멀티채널·데이터증강·모델 블렌딩 기반 시스템들과 통계적으로 차이가 없는 수준을 달성했다. 이는 IBM + cross‑entropy 조합이 마스크 학습에 매우 효율적임을 입증한다.
한계점으로는 IBM이 0/1 이진 마스크이기에, 보컬과 반주가 에너지적으로 거의 동등한 T‑F 셀에서는 라벨링 오류가 발생할 수 있다. 또한 현재 모델은 시간적 연속성을 완전히 활용하지 않으며, RNN·BLSTM과 같은 순환 구조와 결합하면 더 높은 성능이 기대된다. 향후 연구에서는 다중 라벨(보컬 + 악기별) 마스크 학습, 더 큰 데이터셋을 이용한 사전학습, 그리고 실시간 적용을 위한 경량화 방안을 탐색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기