분산된 FAIR 건강 데이터의 책임 있는 분석 프레임워크 구축
초록
본 논문은 네덜란드의 두 기관인 Maastricht Study와 Statistics Netherlands(CBS)의 민감한 건강·사회경제 데이터를 법·윤리·기술적 제약 속에서 연결·분석하기 위한 책임 있는 프레임워크를 제시한다. FAIR 원칙을 기반으로 개인정보 보호를 보장하면서 데이터 연계·분석을 수행하는 세 가지 워크패키지(과학, 기술, ELSI)를 설계·구현하고, Personal Health Train(PHT) 아키텍처와 해시·암호화 기법을 활용한 분산 학습 방식을 제안한다.
상세 분석
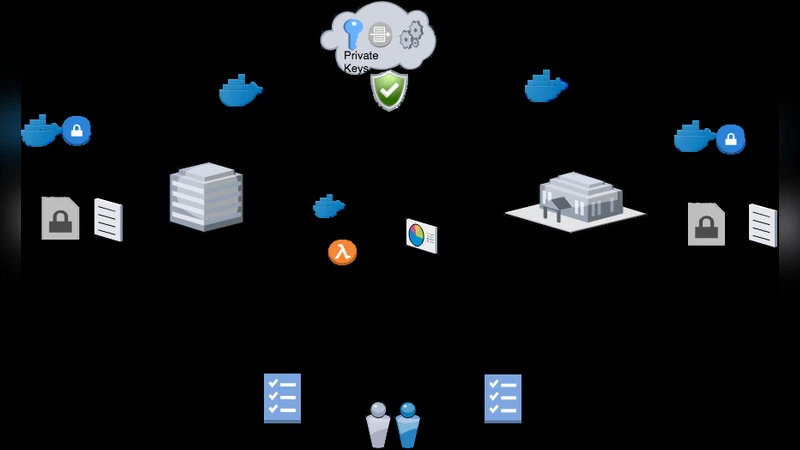
이 연구는 크게 세 가지 차원에서 깊이 있는 분석을 제공한다. 첫째, 법·윤리적 차원에서는 GDPR과 네덜란드 국가법을 정밀히 검토하여 ‘호환 처리(compatible processing)’와 ‘식별자 사용 제한’이라는 핵심 쟁점을 도출한다. 특히, BSN(국가식별번호)의 사용이 금지된 상황에서 연구자는 대체 식별자(연령, 성별, 거주지역 등)를 활용한 의사‑익명화(pseudonymization) 방식을 설계하고, GDPR 제4조에 따라 추가 정보를 별도 보관함으로써 재식별 위험을 최소화한다. 둘째, 기술적 차원에서는 Personal Health Train(PHT)이라는 분산 학습 프레임워크를 채택한다. PHT는 ‘열차(train)’가 각 데이터 제공자(‘역(station)’)을 순회하면서 인증된 알고리즘을 실행하도록 설계돼, 데이터 자체는 이동하지 않고 현장에서 처리된다. 여기서는 Docker 컨테이너 기반의 ‘열차’를 이용해 데이터 추출·전처리·해시·암호화 과정을 자동화하고, 공개키 암호화로 암호화된 데이터셋을 중앙의 Trusted Secure Environment(TSE)로 전송한다. 해시와 소금(salt)을 사전에 공유함으로써 양측에서 동일한 의사‑식별자를 생성하고, 이를 통해 두 데이터셋을 안전하게 매칭한다. 셋째, 과학적 차원에서는 당뇨병 발병과 사회경제적 요인(생활습관, 의료 이용, 교육 수준 등) 간의 연관성을 탐색한다. Maastricht Study에서 제공하는 임상·생활 데이터와 CBS의 의료 이용·보험 청구 데이터가 부분적으로 겹치는 인구집단을 대상으로, 다변량 회귀와 머신러닝 모델을 적용해 변수 간 인과관계를 추정한다. 동시에, 기술 워크패키지에서 구축한 인프라가 정확도, 확장성, 안정성 측면에서 기존 중앙집중식 분석 대비 어느 정도 성능을 유지하는지 벤치마크 테스트를 수행한다. 전체적으로 이 논문은 법·윤리·기술·과학이 상호 보완적으로 작동해야 함을 강조하며, 특히 GDPR 하에서 대규모 민감 데이터의 분산 학습을 실현하기 위한 구체적 절차와 구현 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기