오픈 정보 추출을 위한 로컬 컨텍스트와 글로벌 응집성 통합
초록
본 논문은 기존 오픈 정보 추출(Open IE) 시스템이 문장 내 로컬 컨텍스트에만 의존하는 한계를 극복하기 위해, 대규모 코퍼스의 전역적 통계를 활용하는 새로운 시스템 ‘ReMine’을 제안합니다. ReMine은 외부 지식 베이스의 사실을 원격 감독으로 활용하여, 로컬 문맥 기반의 구문 분할과 전역 응집성을 측정하는 번역 기반 목적 함수를 통합한 최적화 문제를 해결합니다. 서로 다른 두 개의 실제 도메인 코퍼스에서의 실험을 통해 ReMine이 기존 최신 시스템 대비 효과성, 일반성, 강건성을 입증했습니다.
상세 분석
ReMine 프레임워크의 핵심 기술적 혁신은 로컬 신호와 글로벌 신호를 통합한 ‘결합 최적화(Joint Optimization)’ 접근법에 있습니다. 이는 단순히 두 단계를 파이프라인으로 연결하는 것을 넘어, 서로의 오류를 상호 보정하며 성능을 향상시키는 상호 보완적 학습 구조를 구현했습니다.
주요 기술적 통찰은 다음과 같습니다:
-
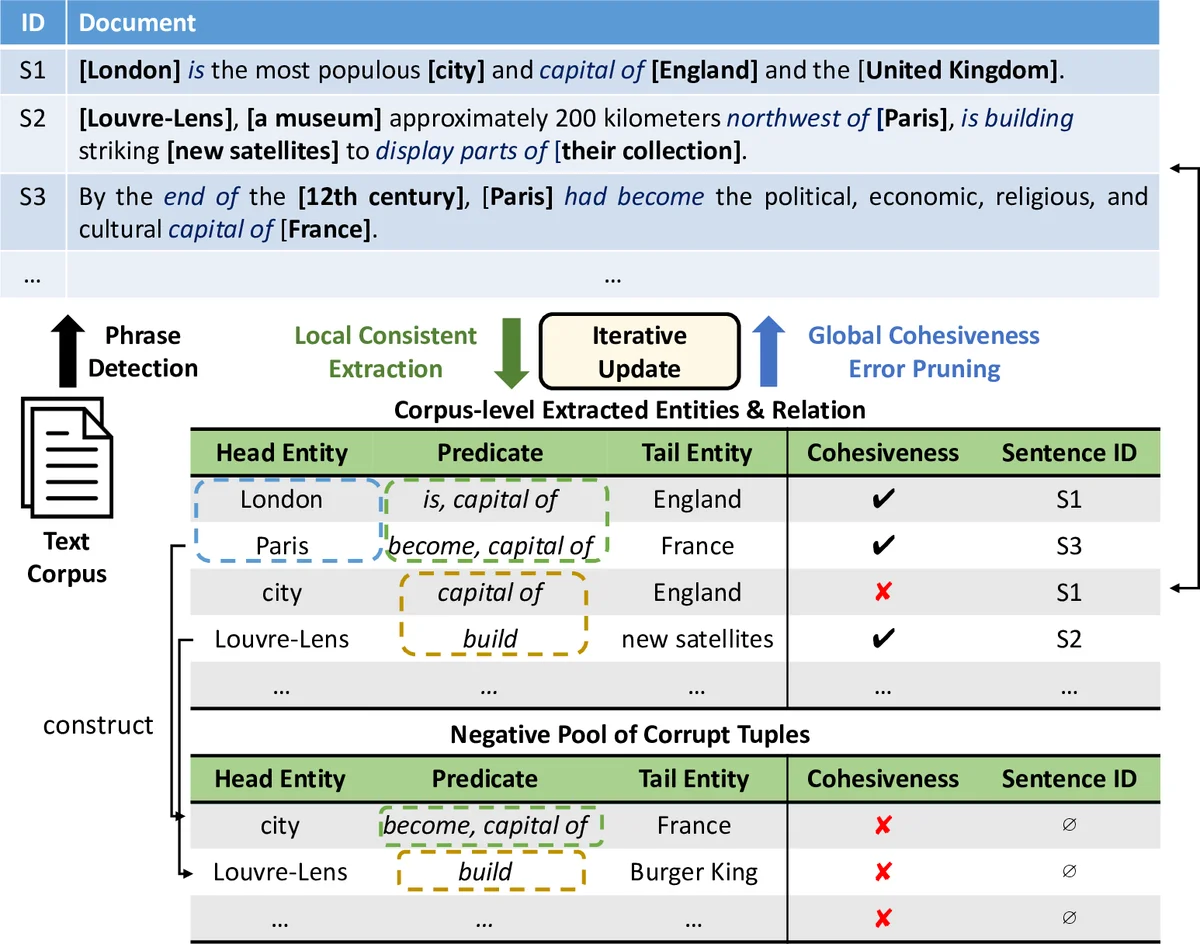
다중 유형 구문 분할(Multi-type Phrasal Segmentation): 기존의 빈도 기반 구문 추출이나 사전 정의된 NP 청커의 한계를 극복합니다. Random Forest 분류기를 활용해 각 구문 세그먼트를 ‘개체 구문’, ‘관계 구문’, ‘배경 텍스트’ 중 하나로 분류하는 확률적 모델을 구축합니다. 이는 외부 지식 베이스의 개체를 양성 샘플로, 코퍼스 내 후보를 음성 샘플로 사용하는 ‘원격 감독’ 방식으로 훈련되어 도메인 독립성을 확보합니다.
-
전역 응집성 모듈의 임베딩 학습: TransE와 유사한 ‘번역(Translating)’ 목적 함수를 채택합니다. 이 모듈은 모든 후보 튜플을 저차원 임베딩 공간에 매핑하여, 유사한 관계 구문이나 개체를 공유하는 개체 구문들이 임베딩 공간에서 가까워지도록 학습합니다. 이를 통해 ‘런던 - 수도 - 영국’과 ‘파리 - 수도 - 프랑스’ 같은 튜플 간의 의미적 유사성을 포착하고, ‘도시 - 수도 - 영국’과 같은 오류 튜플은 응집성 점수가 낮아지도록 조정됩니다.
-
상호 보완적 오류 수정 메커니즘: 튜플 생성 모듈이 생성한 후보(양성 풀)와 의도적으로 왜곡된 샘플(음성 풀)을 글로벌 응집성 모듈에 제공합니다. 응집성 모듈은 이들을 구분하며 학습하고, 계산된 응집성 점수를 다시 튜플 생성 모듈에 피드백합니다. 이 순환 구조는 초기 분할 오류(예: ‘도시’를 개체로 잘못 추출)가 글로벌 통계(‘도시’가 다양한 관계와 결합되어 일관성이 낮음)에 의해 걸러지도록 합니다.
이러한 접근법은 파이프라인 방식에서 발생하는 오류 전파 문제를 근본적으로 해결하며, 사전 정의된 스키마나 도메인 특화 도구에 의존하지 않는 진정한 ‘오픈’ 정보 추출을 가능하게 합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기