딥러닝 기반 소스코드 취약점 자동 탐지
초록
본 논문은 C/C++ 함수 수준의 소스코드를 직접 렉싱한 뒤, 컨볼루션·순환 신경망을 이용해 특징을 학습하고, 이를 랜덤 포레스트와 결합해 취약점 여부를 예측하는 시스템을 제안한다. 1,200만 개 이상의 함수와 정적 분석기 라벨을 활용한 대규모 데이터셋을 구축하고, NIST SATE IV와 실제 패키지 코드를 대상으로 평가해 높은 검출 성능을 입증하였다.
상세 분석
이 연구는 소스코드 취약점 탐지를 위해 기존 정적·동적 분석이 갖는 규칙 기반 한계를 딥러닝으로 극복하고자 한다. 먼저 저자들은 C/C++ 함수들을 156개의 토큰으로 압축하는 맞춤형 렉서를 설계했는데, 이는 키워드·연산자·구분자를 모두 포함하면서 식별자와 리터럴을 일반화하여 어휘 규모를 최소화한다. 이렇게 표준화된 토큰 시퀀스는 자연어 처리(NLP)에서 사용되는 임베딩 기법과 유사하게 k‑차원(최적 k=13) 벡터로 변환된다. 임베딩 단계에서는 무작위 초기화가 가장 좋은 성능을 보였으며, word2vec 사전학습 모델은 큰 개선을 제공하지 못했다는 점이 흥미롭다.
특징 추출은 두 가지 경로를 탐색한다. 첫 번째는 9개의 토큰을 한 번에 보는 512개의 컨볼루션 필터(CNN)이며, 배치 정규화와 ReLU 활성화를 적용해 지역 패턴을 효과적으로 포착한다. 두 번째는 2‑계층 GRU(또는 LSTM) RNN으로, 장거리 토큰 의존성을 학습한다. 두 방법 모두 max‑pooling을 통해 가변 길이 시퀀스를 고정 차원 벡터로 압축한다. 이후 64와 16 유닛의 완전 연결 계층을 거쳐 softmax 출력으로 취약점 확률을 산출한다.
특히 저자들은 신경망 자체보다 랜덤 포레스트(RF)와 결합했을 때 성능이 크게 향상된다는 점을 강조한다. 신경망이 추출한 n‑차원 특징 벡터를 RF에 입력함으로써 과적합을 억제하고, 비선형 결정 경계를 보다 정교하게 모델링한다. 학습 과정에서는 토큰 길이가 10~500 사이인 함수만 사용하고, 클래스 불균형을 보정하기 위해 취약 함수에 가중치를 부여하였다.
데이터 측면에서는 세 가지 출처(SATE IV Juliet, Debian, GitHub)에서 총 12.1 M개의 함수를 수집하고, 중복 제거와 컴파일‑레벨 특징(제어 흐름 그래프, opcode 벡터, use‑def 매트릭스) 기반 필터링을 통해 최종 1.08 M개의 고유 함수를 확보했다. 라벨링은 Clang, Cppcheck, Flawfinder 등 세 정적 분석기의 결과를 CWE 매핑 후 필터링해 ‘취약’·‘비취약’ 이진 라벨을 생성했으며, 전체 라벨링 비율은 약 6.8%였다.
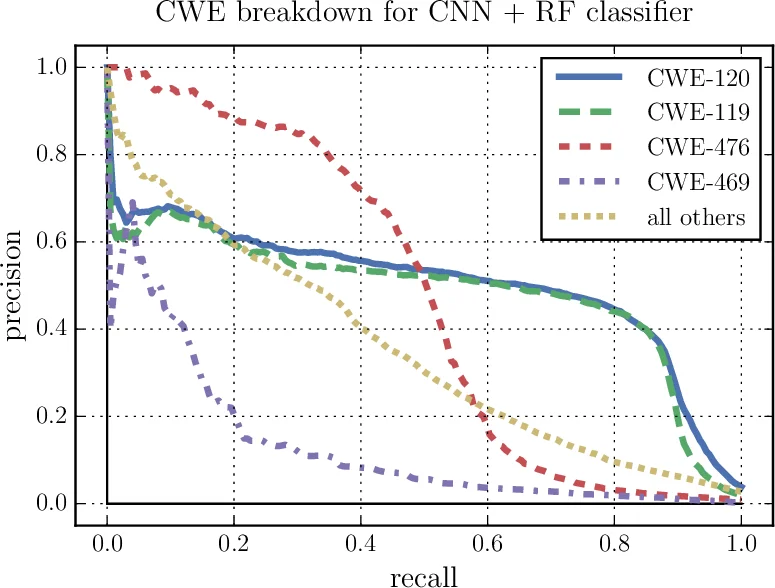
평가에서는 실제 소프트웨어 패키지와 NIST SATE IV 벤치마크를 사용해 정확도, 재현율, F1‑score 등을 측정했으며, 제안 모델이 기존 SVM·Bag‑of‑Words 기반 방법보다 우수한 결과를 보였다. 특히 CNN‑RF 조합이 가장 높은 검출률을 기록했으며, RNN‑RF도 경쟁력 있는 성능을 나타냈다. 이러한 결과는 대규모 자연 코드와 딥러닝 기반 특징 학습이 취약점 탐지에 실용적이며 확장 가능함을 시사한다.
한계점으로는 라벨링에 정적 분석기에 의존함으로써 라벨 품질이 분석기 정확도에 좌우된다는 점, 그리고 함수 수준 라벨링이 실제 취약점의 컨텍스트(예: 호출 관계)를 완전히 반영하지 못한다는 점을 들 수 있다. 향후 연구에서는 동적 분석·버그 추적 데이터와 결합한 멀티모달 라벨링, 그리고 함수 간 관계를 모델링하는 그래프 신경망(GNN) 적용이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기