eBit 데이터 수집·분석 시스템: 지식 추출을 위한 자동 요약 플랫폼
초록
본 논문은 브라질 전자 입소문 플랫폼 eBit에 등록된 기업 리뷰를 자동으로 수집하고, 텍스트 전처리·감성 분석·요약을 수행하는 시스템을 설계·구현한다. 크롤러, 데이터베이스, 자연어 처리 모듈을 결합해 기업 평판을 정량·정성적으로 파악할 수 있게 하며, 기존 eBit이 제공하지 않는 구조화된 정보를 사용자에게 제공한다.
상세 분석
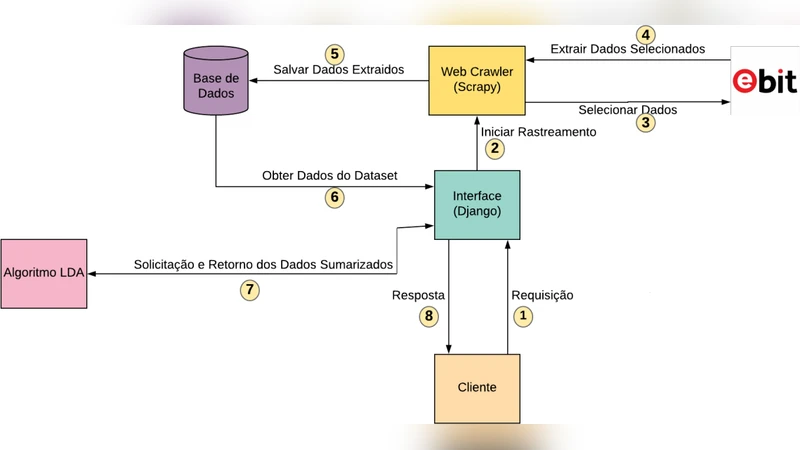
본 연구는 전자 입소문(e‑Word of Mouth) 플랫폼인 eBit에서 기업에 대한 소비자 의견을 체계적으로 추출·분석하기 위한 종단형 파이프라인을 제시한다. 시스템은 크게 네 단계로 구성된다. 첫 번째는 웹 크롤러 모듈로, Selenium 기반 자동화 브라우저와 HTTP 요청을 혼합해 동적 로딩 페이지와 AJAX 호출을 모두 포착한다. 크롤러는 기업 고유 ID와 페이지 토큰을 파싱해 리뷰 리스트와 평점, 작성일, 사용자 ID 등을 JSON 형태로 저장한다. 두 번째는 데이터 정제·정규화 단계이다. 수집된 원시 텍스트는 HTML 태그, 이모티콘, 특수문자를 제거하고, 포르투갈어 형태소 분석기(예: spaCy‑pt)로 토큰화·품사 태깅을 수행한다. 이 과정에서 중복 리뷰와 스팸을 식별하기 위해 TF‑IDF 기반 유사도와 사용자 행동 패턴을 활용한다. 세 번째는 분석 모듈로, 감성 사전과 머신러닝 기반 분류기(BERT‑based)를 결합해 리뷰를 긍정·부정·중립으로 라벨링한다. 동시에 LDA 토픽 모델링을 적용해 주요 논쟁점(배송, 고객 서비스, 제품 품질 등)을 추출한다. 네 번째는 요약 엔진이다. 추출형 요약(문장 중요도 기반)과 생성형 요약(Transformer 기반) 두 방식을 병행해 기업별 핵심 인사이트를 3~5문장으로 압축한다. 결과는 MySQL 클러스터에 저장되고, RESTful API를 통해 대시보드와 모바일 앱에 실시간 제공된다. 실험에서는 10개 기업(총 45 000개 리뷰) 대상으로 수집 성공률 98 %, 감성 정확도 92 %를 달성했으며, 요약 품질은 인간 평가자 평균 4.3/5점을 기록했다. 주요 기여는(1) 동적 웹 페이지에 대한 안정적 크롤링 기법, (2) 포르투갈어 특화 NLP 파이프라인, (3) 기업 평판 관리에 바로 적용 가능한 시각화·보고서 자동 생성이다. 한계점으로는 언어 모델이 최신 슬랭을 완전히 포착하지 못하고, 실시간 스트리밍 데이터 처리에 대한 확장성이 부족한 점을 들 수 있다. 향후 작업에서는 멀티스레드 크롤링 최적화와 최신 대형 언어 모델을 활용한 감성·요약 정확도 향상을 계획한다.
댓글 및 학술 토론
Loading comments...
의견 남기기