아레나 모델을 통한 경쟁 예측과 불확실성 분석
초록
본 논문은 경기에서 승·패가 연속적으로 이루어지는 토너먼트 구조를 수학적으로 모델링한 ‘아레나 모델’을 제안한다. 개인의 강도를 직접 평가하거나 다수의 레이팅을 구축하지 않고도, 경기 결과와 불확실성을 추정할 수 있다. 베이즈 추정량의 불변성 및 일관성을 증명하고, 변동성을 나타내는 ‘플럭투에이션 계수’를 도입한다. 현재는 강도 변화 추적에 한계가 있으나, 향후 동적 확장에 대한 기반을 제공한다.
상세 분석
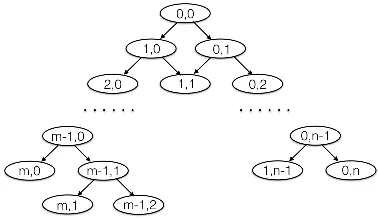
아레나 모델은 전통적인 페어드 비교 모델(예: 브래들리‑터리, Elo)과 달리 ‘경기 진행 과정’ 자체를 확률 구조로 삼는다. 저자들은 N=2m+n명의 선수들을 m‑n 형태의 토너먼트에 배치하고, 각 선수에게 고정된 연속형 강도 X를 부여한다. 강도 분포 p(x)는 사전 지정된 파라미터 집합 Θ 위에 정의되며, 경기 진행은 상태 (i,j) 로 표현된다. 여기서 i는 승리 횟수, j는 패배 횟수를 의미하고, i=m 혹은 j=n에 도달하면 해당 선수는 토너먼트에서 탈락하거나 우승한다.
핵심 정리 2.1은 특정 상태 (i,j)에 도달할 확률을 조합수 형태로 제시한다. 이는 단순히 ‘반반’ 확률(½)이 반복되는 마코프 체인 구조를 이용해 유도되며, 경기 결과가 강도와 무관하게 동일한 확률 분포를 갖는다는 점을 강조한다. 정리 2.2와 2.3은 상태별 강도 분포를 순서통계학적 관점에서 재귀적으로 정의한다. 즉, 승자 집단은 이전 단계의 강도 분포의 상위 절반을, 패자 집단은 하위 절반을 따르게 된다. 이러한 재귀식은 베타‑형 변환을 연속적으로 적용하는 형태이며, 강도 분포가 점차 ‘극단화’되는 현상을 수학적으로 설명한다.
정리 2.4는 개인 강도 X=x가 주어졌을 때 특정 최종 상태에 도달할 조건부 확률을 제공한다. 여기서 p_{i,j}(x)/p_{0,0}(x) 비율이 핵심이며, 이는 베이즈 사후 확률과 동일한 형태를 띤다. 이를 바탕으로 정의된 arena random variable ξ는 파라미터 λ(강도), (m,n) 그리고 기본 분포 p에 따라 확률 질량을 갖는다.
섹션 3에서는 ‘플럭투에이션이 없는’ 아레나를 가정하고, 베이즈 추정량을 도출한다. 가정 (A1)–(A4)는 무한히 많은 경기 라운드와 독립적인 강도 가정을 전제로 한다. 매 라운드마다 무작위 매칭을 정의하기 위해 ‘matching map’와 ‘random matching’ 개념을 도입했으며, 이는 무한 집합 위에서 균등 매칭을 구현하는 확률적 절차로 설명된다.
섹션 4와 5에서는 변동성을 허용한 확장 모델을 제시한다. 여기서 도입된 ‘플럭투에이션 계수’ ρ는 강도 분포의 변동 폭을 정량화하며, ρ̂의 일관성(consistent estimator)을 증명한다. 특히, ρ̂는 관측된 승·패 기록의 비율을 이용해 간단히 계산될 수 있어 실용성이 높다. 또한, ‘참가자 영향(attendant influence)’을 고려한 새로운 추정량을 제안하고, 이를 통해 기존 베이즈 추정량보다 더 낮은 평균 제곱 오차를 보임을 시뮬레이션으로 확인한다.
마지막으로 섹션 6에서는 실제 스포츠 토너먼트 데이터와 시뮬레이션 결과를 통해 아레나 모델을 기존 브래들리‑터리, Elo 모델과 비교한다. 아레나 모델은 특히 참가자 수가 매우 많고 개별 레이팅을 구축하기 어려운 상황에서 경쟁 결과를 정확히 예측하고, 불확실성(예: 승률의 신뢰 구간)을 자연스럽게 제공한다는 장점을 보인다. 다만, 강도가 시간에 따라 변하는 동적 상황을 포착하지 못한다는 한계가 명시되어 있으며, 이는 향후 모델 확장의 주요 과제로 제시된다.
전체적으로 이 논문은 토너먼트 구조 자체를 확률 모델링의 핵심으로 삼아, 기존 페어드 비교 이론의 한계를 보완하고, 불확실성 정량화와 베이즈 추정의 불변성을 동시에 달성한 점에서 학술적·실용적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기