쿼터니언 신경망으로 보는 효율적인 음성 인식
본 논문은 멜 필터뱅크와 1·2차 미분값을 하나의 4차원 쿼터니언으로 묶어 입력으로 사용하고, 이를 처리하는 QCNN과 QRNN을 기존 실수값 CNN·RNN과 비교한다. TIMIT 데이터셋 실험에서 쿼터니언 모델이 파라미터는 최대 3.96배 적게 사용하면서도 음소 오류율(PER)을 0.5~0.6%p 향상시키는 것을 확인하였다.
저자: Titouan Parcollet, Mirco Ravanelli, Mohamed Morchid
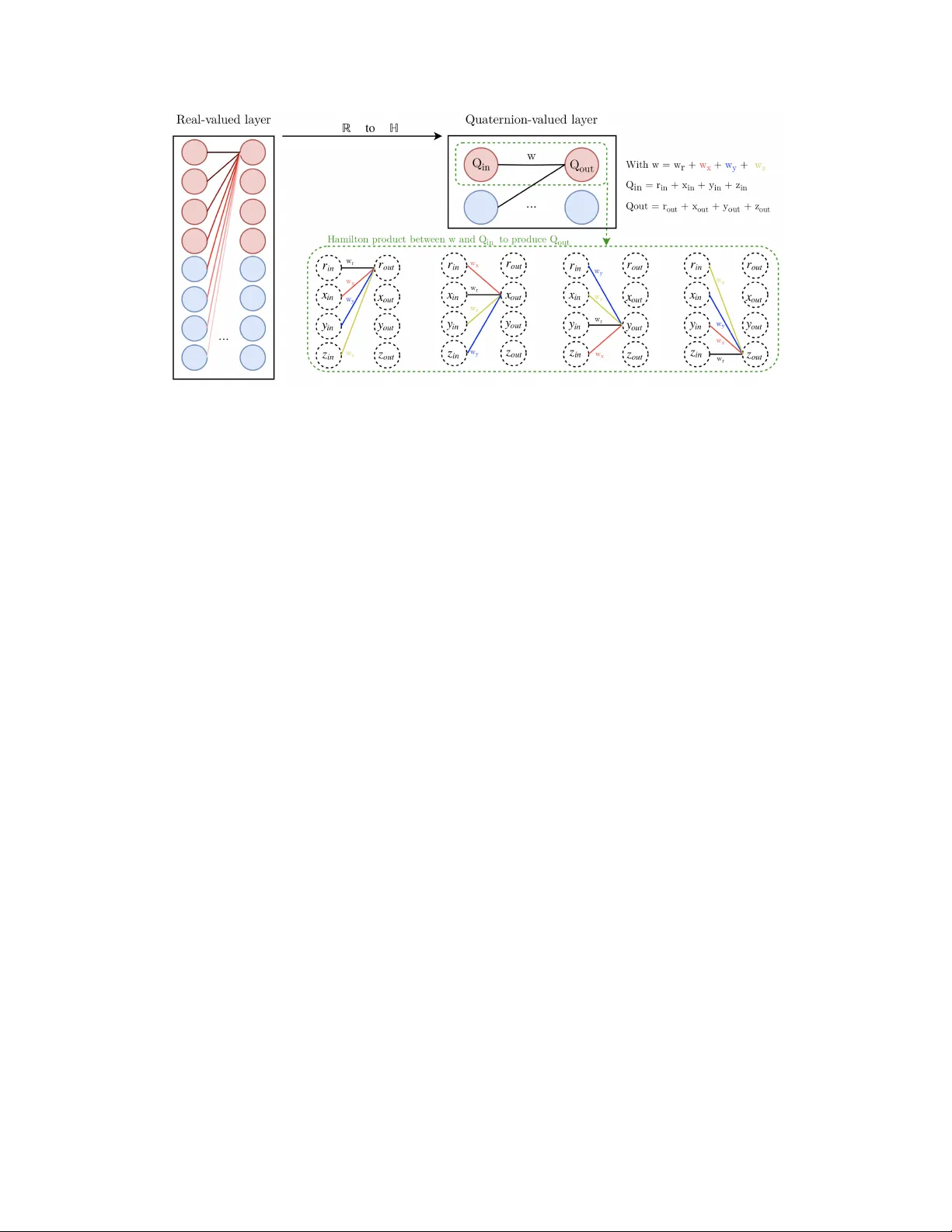
본 연구는 현대 자동 음성 인식(ASR) 시스템에서 사용되는 멜 필터뱅크 에너지와 그 1·2·3차 시간 미분값을 하나의 4차원 쿼터니언으로 묶어 입력으로 활용하고, 이를 처리하는 쿼터니언 기반 컨볼루션 신경망(QCNN)과 순환 신경망(QRNN)을 제안한다. 기존 실수값 신경망은 다차원 특성을 단순히 연결된 벡터로 취급해 내부 의존성을 별도 메커니즘 없이 학습하도록 강요한다. 반면, 쿼터니언은 네 개의 실수 성분을 하나의 하이퍼복소수로 결합해, 같은 시간 프레임 내의 서로 연관된 특성들을 하나의 엔터티로 다룰 수 있다.
논문은 먼저 쿼터니언 대수의 기본 개념을 소개한다. 쿼터니언 Q = r + xi + yj + zk는 실수 부분 r과 세 개의 허수 부분(i, j, k)으로 구성되며, 해밀턴 곱(⊗)을 통해 두 쿼터니언 간의 곱셈이 정의된다. 해밀턴 곱은 각 성분 간의 교차 결합을 포함해 가중치가 네 차원 전체에 공유되도록 하므로, 내부 관계를 자연스럽게 인코딩한다.
다음으로 QCNN 구조를 설명한다. 전통적인 2‑D 컨볼루션 연산을 해밀턴 곱으로 대체하고, 각 레이어의 출력에 스플릿 활성화 함수 α(Q)=f(r)+f(x)i+f(y)j+f(z)k 를 적용한다. 이렇게 하면 실수값 활성화 함수 f를 그대로 재사용하면서도 쿼터니언 성분별 비선형 변환이 가능하다. 출력층은 필요에 따라 실수값 소프트맥스로 변환해 CTC 손실을 적용한다.
QRNN은 순환 구조에 해밀턴 곱을 적용한 형태이다. 입력‑숨김, 숨김‑숨김, 숨김‑출력 가중치를 모두 쿼터니언 행렬로 정의하고, 각 시간 단계에서 h_t = α(∑ w_hh⊗h_{t‑1}+∑ w_hγ⊗x_t+b) 로 업데이트한다. 출력 γ_t 역시 스플릿 활성화 β를 통해 계산된다. 역전파는 기존 RNN의 BPTT와 동일한 흐름을 따르지만, 쿼터니언 미분 규칙을 적용한다.
실험은 TIMIT 데이터셋을 사용해 두 가지 설정에서 수행되었다. (1) 엔드‑투‑엔드 CTC 기반 모델에서는 QCNN과 CNN을 비교했으며, (2) 전통적인 HMM‑디코딩 파이프라인에서는 QRNN과 RNN을 비교했다. 입력 전처리는 40차원 로그 멜 스펙트럼에 1·2·3차 미분을 추가해 160차원 실수 벡터를 만든 뒤, 4차원씩 묶어 40개의 쿼터니언으로 변환하였다.
결과는 다음과 같다. QCNN은 PER 19.5%를 달성해 동일 구조의 CNN(20.6%)보다 1.1%p 낮은 오류율을 보였으며, 파라미터 수는 약 4배 감소했다. QRNN은 PER 18.5%로 RNN(19.0%)보다 0.5%p 개선했으며, 파라미터 감소율은 3.96배에 이른다. 파라미터 절감에도 불구하고 성능이 향상된 이유는 해밀턴 곱을 통한 내부 의존성 학습과, 쿼터니언이 제공하는 회전·스케일 불변성에 있다. 또한, 파라미터가 적어 과적합 위험이 낮아 데이터가 제한된 상황에서도 일반화가 용이함을 확인했다.
논문은 이러한 결과를 바탕으로, 쿼터니언 기반 모델이 음성 신호의 다차원 특성을 보다 효율적으로 표현하고 학습할 수 있음을 주장한다. 향후 연구 방향으로는 다중 모달 입력(예: 스펙트로그램과 텍스트 임베딩) 결합, 더 깊은 하이퍼컴플렉스 구조(옥타리온 등) 적용, 그리고 대규모 코퍼스에서의 스케일링을 제시한다. 최종적으로, 쿼터니언 신경망은 파라미터 효율성과 성능 향상을 동시에 달성할 수 있는 유망한 대안으로 자리매김한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기