이미지 품질 평가에서 부스팅 기법의 효과와 일반화 가능성
초록
본 논문은 11개의 서로 다른 이미지 품질 평가(IQA) 알고리즘을 다중 방법 융합(fusion)하여 부스팅 효과를 검증한다. 지원 벡터 머신(SVM)과 신경망(NN) 두 가지 회귀 모델을 사용해 성능을 비교하고, LIVE, MULTI‑LIVE, TID2013 데이터베이스에서 5‑fold 교차 검증을 수행한다. 실험 결과, 부스팅은 전반적으로 정확도·선형성·순위 측면에서 기존 단일 방법보다 우수했으며, 특히 두 개 이상의 방법을 결합할 때 신경망 기반 부스팅이 SVM 기반보다 더 큰 향상을 보였다.
상세 분석
이 연구는 이미지 품질 평가 분야에서 “약한 학습기(weak learner)를 강한 학습기(strong learner)로 전환한다”는 부스팅 개념을 기존의 다중 방법 융합에 적용한 점이 가장 큰 특징이다. 먼저 저자들은 11개의 IQA 알고리즘을 다섯 개 카테고리(피델리티, 퍼셉추얼 피델리티, 구조적 유사성, 색상, 학습 기반)로 분류하였다. 피델리티 기반에서는 PSNR, PSNR‑HA, PSNR‑HMA 등을, 구조적 유사성 기반에서는 SSIM, MS‑SSIM, CW‑SSIM, IW‑SSIM, SR‑SIM을, 색상 기반에서는 FSIMc와 PerSIM을, 학습 기반에서는 비지도 학습 방식인 UNIQUE를 사용하였다.
부스팅 모델은 두 가지로 제한했는데, 하나는 선형 커널을 갖는 SVM이며, 다른 하나는 은닉층 뉴런 수를 사용된 IQA 알고리즘 수와 동일하게 설정한 다층 퍼셉트론이다. 학습 과정에서 손실 함수는 평균 제곱 오차(MSE)이며, SVM은 SMO 최적화 알고리즘을, NN은 Levenberg‑Marquardt 방식을 적용하였다.
데이터는 세 개의 표준 IQA 데이터베이스(LIVE, MULTI‑LIVE, TID2013)를 사용했으며, 각 데이터베이스는 압축, 노이즈, 통신, 블러, 색상, 전역·국부 왜곡 등 7가지 왜곡 카테고리로 구성된다. 5‑fold 교차 검증을 100번 반복함으로써 통계적 신뢰성을 확보하였다. 성능 평가는 RMSE(정확도), Pearson 상관계수(선형성), Spearman 상관계수(순위)와 ITU‑T P.1401 기반의 통계적 유의성 검정을 포함한다.
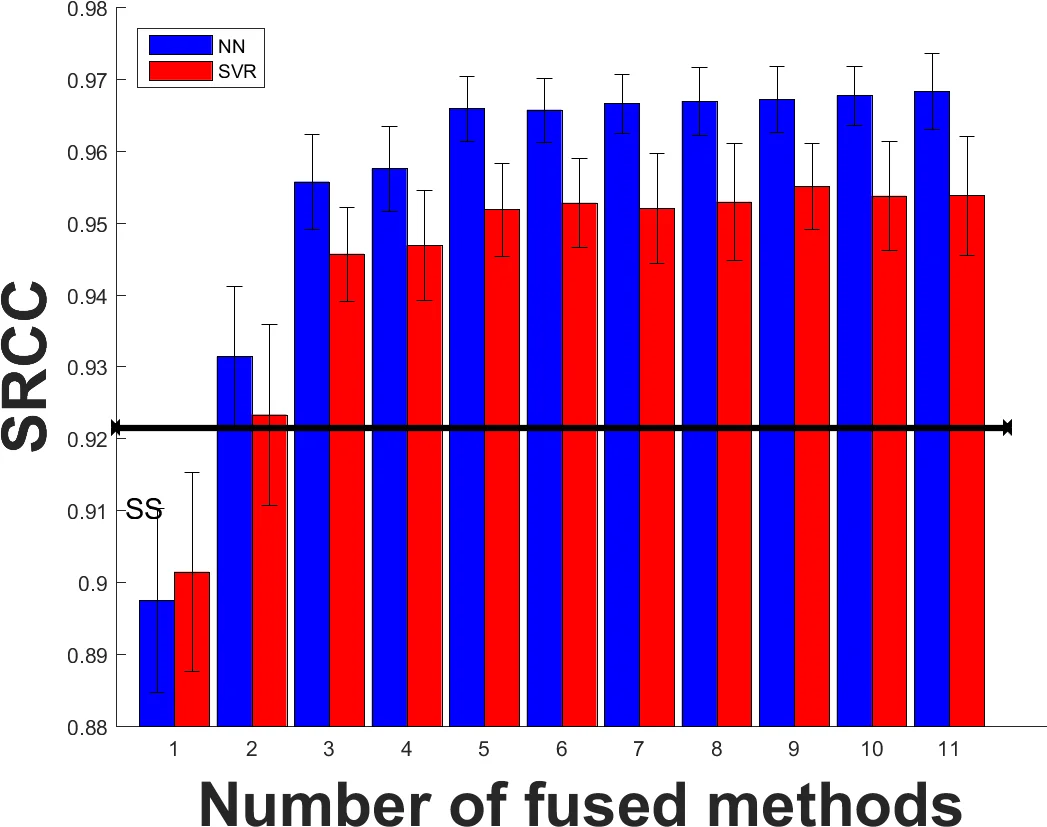
실험 결과는 크게 세 가지로 요약된다. 첫째, 개별 IQA 알고리즘 중에서는 PSNR‑HMA, SR‑SIM, IW‑SSIM, UNIQUE가 각각 LIVE, MULTI‑LIVE, TID2013 데이터베이스에서 최고 성능을 보였다. 둘째, 부스팅을 적용하면 대부분의 경우 RMSE와 Pearson이 개선되었으며, 특히 구조적·스펙트럼·학습 기반 방법에서 큰 향상이 관찰되었다. 셋째, 두 개 이상의 방법을 결합할 때 신경망 기반 부스팅이 SVM 기반보다 일관되게 높은 Pearson·Spearman 값을 기록했으며, 최악의 성능을 보이는 알고리즘을 다른 두 개 이상의 방법과 결합하면 통계적으로 유의한 성능 향상이 나타났다.
이러한 결과는 부스팅이 특정 알고리즘에 국한되지 않고, 다양한 IQA 방법을 포괄적으로 결합함으로써 전반적인 품질 예측 능력을 향상시킬 수 있음을 시사한다. 또한, 복잡한 딥러닝 모델을 사용하지 않고도 비교적 간단한 NN 구조만으로도 SVM보다 우수한 결과를 얻을 수 있음을 보여, 실시간 혹은 자원 제한 환경에서도 적용 가능함을 암시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기