밀도 기반 도시 형태 발생 모델의 보정
초록
본 논문은 도시 성장의 핵심 메커니즘을 ‘집합(선호적 부착)’과 ‘확산(스프롤)’ 두 가지 추상 과정으로 단순화한 확률적 메조스케일 모델을 제시한다. 50 km 정사각형 창을 이용해 EU 전역의 인구 밀도 데이터를 정량화하고, 네 가지 형태 지표(계급‑크기 기울기, 엔트로피, 모란 지수, 평균 거리)를 계산한다. 파라미터 공간을 광범위히 탐색·보정한 결과, 실제 관측된 다양한 도시 형태를 모델이 재현할 수 있음을 확인한다.
상세 분석
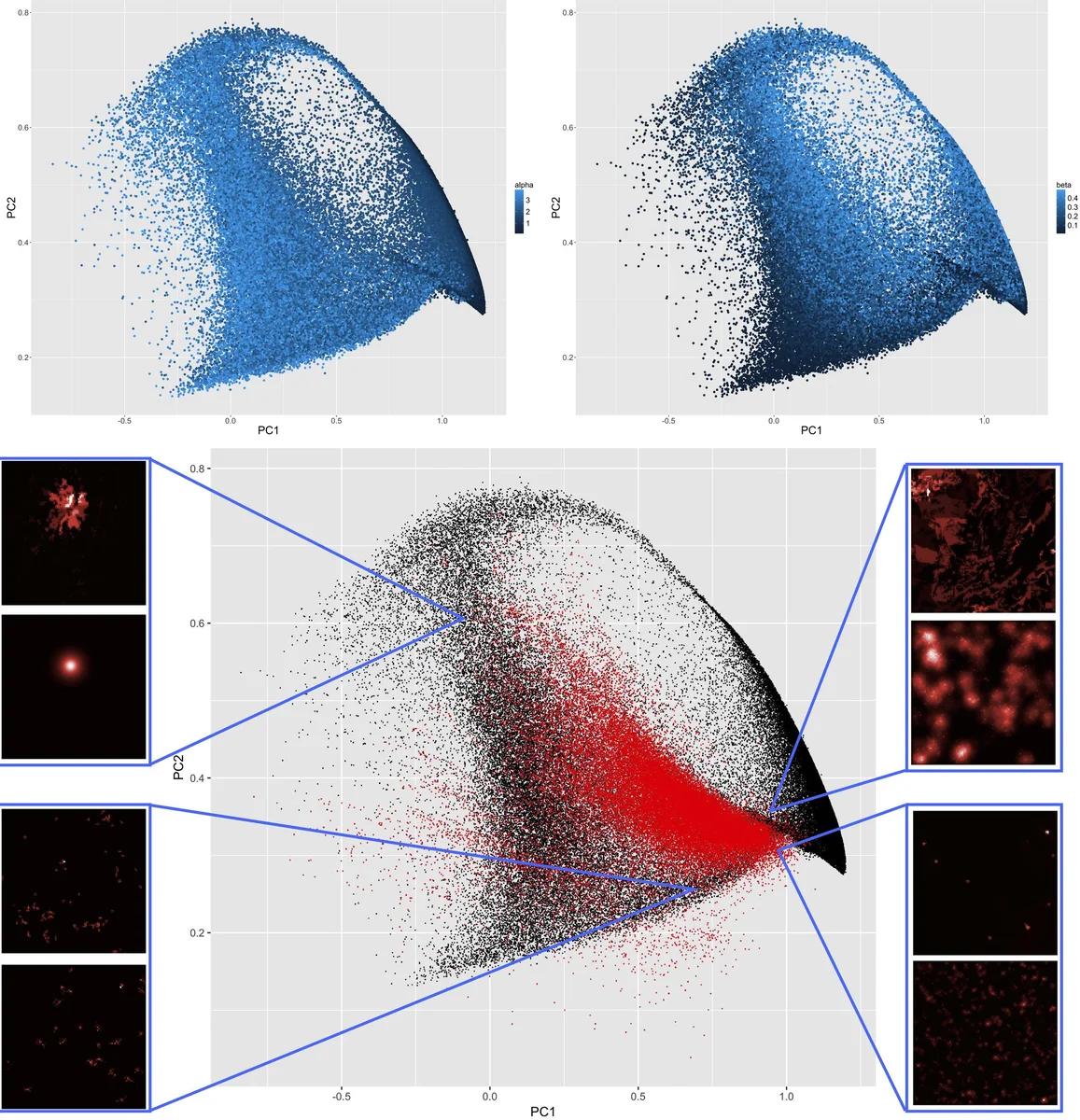
이 연구는 도시 형태를 설명하는 복잡한 사회‑경제적 요인을 최소화하고, 두 개의 물리‑수학적 프로세스인 집합(aggregation)과 확산(diffusion)만으로도 메조스케일(≈50 km)에서 관측되는 형태 변이를 충분히 포착할 수 있음을 실증한다. 모델은 격자(N×N, N=100) 위에 인구 P_i(t)를 배치하고, 매 시간 단계마다 총 인구를 고정 성장률 N_G만큼 증가시킨 뒤, 현재 인구 비율에 따라 선호적 부착 확률 α를 적용해 새로운 인구 단위를 할당한다. 이후 β와 n_d에 의해 인구가 8방향 이웃으로 균등하게 확산된다. 파라미터 범위는 P_m(10^4‑10^6), N_G(500‑30000), α(0.1‑4), β(0‑0.5), n_d(1‑5)로 설정돼, 실제 도시 성장 속도와 규모를 반영한다.
형태 정량화는 네 가지 지표로 구성된다. 첫째, 계급‑크기 기울기 γ는 인구 분포의 계층성을 로그‑선형 회귀로 측정한다. 둘째, 엔트로피 E는 인구 집중 정도를 정보 이론적 관점에서 평가한다(단일 셀 집중 시 E→0, 균등 분포 시 E→log M). 셋째, 모란 지수 I는 공간 자기상관을 1/d_ij 가중치로 계산해 밀집 중심과 분산 패턴을 구분한다. 넷째, 평균 거리 d̄는 인구 쌍 간 거리의 가중 평균으로, 전체적인 집중도를 직관적으로 나타낸다.
실제 데이터는 Eurostat의 100 m 해상도 인구 격자를 500 m로 집계하고, 50 km 정사각형 창을 10 km 간격으로 겹치게 배치해 전 EU에 대해 지표를 산출했다. 프랑스 사례를 시각화한 결과, 대도시권은 높은 모란값과 낮은 엔트로피를 보이며, 남부·북부 농촌은 계급‑크기 기울기와 평균 거리에서 뚜렷한 지역 차이를 나타냈다. k‑means 군집(k=5)과 주성분 분석을 통해 ‘대도시·산악·북부 농촌·남부 농촌·중부 혼합’ 등 다섯 가지 형태 클러스터가 도출되었다.
모델 탐색에서는 81개의 파라미터 조합에 대해 100번씩 시뮬레이션을 수행해 수렴성 및 변동성을 평가했다. 결과는 α가 클수록 높은 모란값과 낮은 엔트로피를, β와 n_d가 클수록 평균 거리가 증가하고 형태가 더 확산되는 경향을 보였다. 특히 P_m/N_G 비율이 최종 인구 밀도 패턴을 결정하는 핵심 요인으로 작용한다는 점이 확인되었다.
보정 단계에서는 실제 지표 분포와 시뮬레이션 결과 간의 유클리드 거리 최소화를 목표 함수로 설정하고, 파라미터 공간을 탐색했다. 최적 파라미터 집합은 지역별 클러스터 특성에 맞춰 α와 β를 조정함으로써, 모델이 거의 모든 관측 형태를 재현함을 보여준다. 이는 집합‑확산 메커니즘만으로도 도시 형태의 다변성을 설명할 수 있음을 강력히 시사한다.
이 논문은 모델 구현을 NetLogo와 Scala(고성능 컴퓨팅 연동)로 제공하고, 데이터와 코드를 공개함으로써 재현 가능성을 높였다. 또한 형태 지표의 선택과 정규화, 창 크기·해상도 민감도 분석을 통해 방법론적 견고함을 확보했다. 향후 연구에서는 교통·경제·환경 변수와의 통합, 시간적 동역학(예: 정책 충격) 분석을 통해 모델의 확장성을 검증할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기