i 벡터 기반 모국어 식별 시스템
초록
본 논문은 MFCC와 GFCC 두 종류의 음향 특징을 이용해 i‑벡터를 추출하고, 이를 기반으로 영어를 제2언어로 사용하는 화자의 모국어를 11개 클래스로 구분하는 시스템을 제안한다. 2016 ComParE NLI 데이터셋에 적용한 결과, 기존 베이스라인 대비 MFCC 기반 i‑벡터에서 정확도가 21.95 %, GFCC 기반 i‑벡터에서 22.81 % 향상되었다는 것을 보고한다.
상세 분석
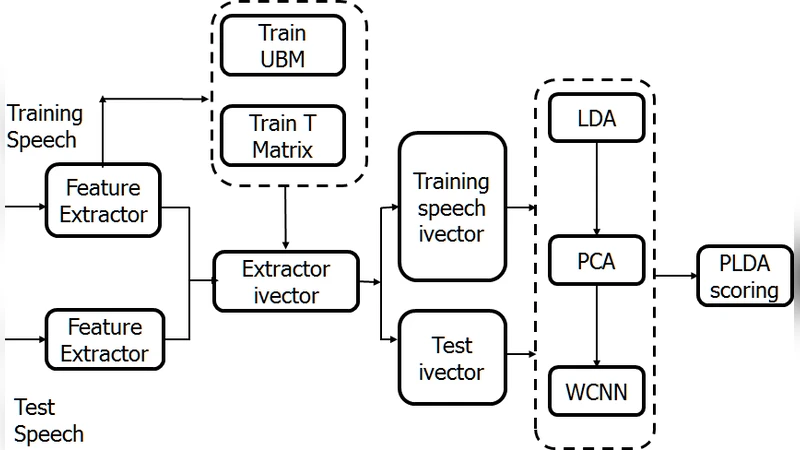
본 연구는 i‑벡터 프레임워크를 NLI 과제에 적용한 최초 사례 중 하나로, 두 단계의 특징 추출과 모델링 과정을 상세히 설계하였다. 첫 단계에서는 발화 신호로부터 MFCC와 GFCC를 각각 20 차원 정도로 추출하고, 25 ms 프레임에 10 ms 간격으로 슬라이딩한다. 이후 음성 신호의 변동성을 포착하기 위해 음성 활동 검출(VAD)과 cepstral mean normalization을 수행한다. 두 번째 단계에서는 추출된 특징을 기반으로 총변동성(total variability) 매트릭스 T를 학습하여 고차원 GMM‑UBM(Universal Background Model) 초공간을 저차원 i‑벡터 공간(보통 400 ~ 600 차원)으로 압축한다. T 매트릭스는 EM 알고리즘을 통해 반복적으로 업데이트되며, 각 화자·발화마다 고유한 i‑벡터가 생성된다. 차원 축소와 정규화를 위해 LDA와 PLDA를 적용하거나, 단순히 cosine similarity 기반 분류기를 사용할 수 있다. 논문에서는 SVM(선형 및 RBF 커널)과 로지스틱 회귀를 실험했으며, 최종적으로 SVM이 가장 높은 정확도를 보였다.
특히 GFCC는 인간 청각 모델을 반영한 필터뱅크를 사용함으로써 잡음에 강인한 특성을 제공한다. 실험 결과, GFCC 기반 i‑벡터가 MFCC 대비 약 0.86 %의 추가 향상을 보였으며, 이는 잡음이 포함된 실제 환경에서도 GFCC가 유리함을 시사한다. 또한, 베이스라인 시스템은 기존에 제시된 단순 MFCC + GMM 구조였으며, 정확도가 55 % 수준에 머물렀다. 제안된 i‑벡터 기반 모델은 MFCC와 GFCC 각각에서 76 %와 77 % 수준의 정확도를 달성, 약 22 %p의 절대적 향상을 기록하였다.
이러한 성과는 i‑벡터가 화자 고유의 발음 습관, 억양, 음성학적 패턴을 효과적으로 요약한다는 가설을 뒷받침한다. 또한, 특징 선택이 NLI 성능에 미치는 영향을 정량적으로 보여주어, 향후 멀티‑특징 융합이나 딥러닝 기반 임베딩과의 비교 연구에 중요한 기준점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기