분산 컴퓨팅을 위한 자율 침입 대응 시스템
초록
본 논문은 클라우드·엣지 환경에서 발생하는 대규모 로그 데이터를 실시간으로 분석하고, 기대 효용 기반 의사결정을 통해 자동으로 침입에 대응하는 자율 침입 대응 시스템(SARI)을 제안한다. MAP‑K 구조와 MapReduce 기반 분석 파이프라인을 활용해 공격 탐지·분류·계획·실행을 통합하고, 프로토타입 구현과 퍼블릭·프라이빗 클라우드 실험을 통해 응답 시간 및 확장성에서 기존 IDS 대비 우수함을 입증한다.
상세 분석
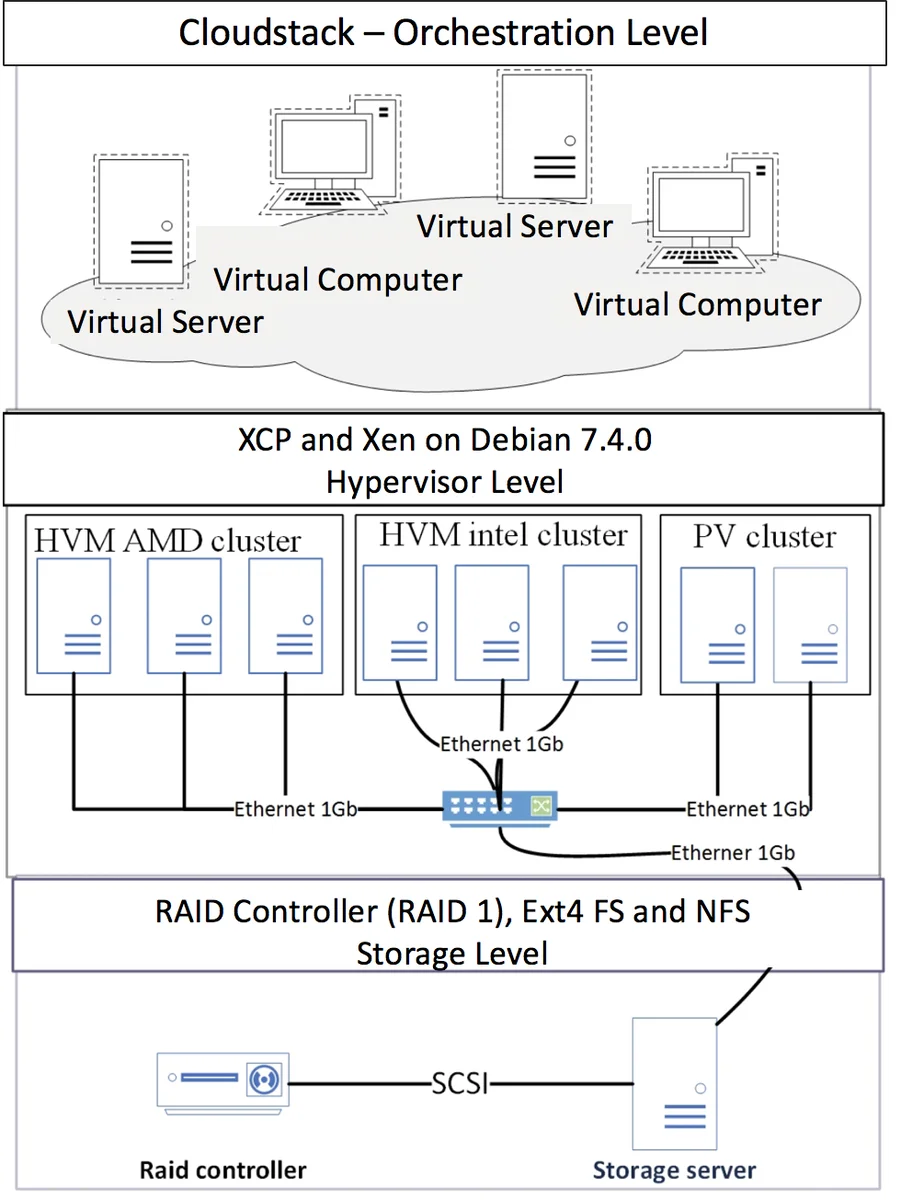
본 연구는 자율 컴퓨팅(Autonomic Computing)과 빅데이터 처리 기술을 결합한 새로운 침입 대응 프레임워크를 제시한다는 점에서 의의가 크다. 먼저, 시스템은 전통적인 MAPE‑K 루프를 확장한 MAP‑K(모니터‑분석‑계획‑실행‑지식) 아키텍처를 채택한다. 모니터링 모듈은 VM, 하이퍼바이저, 네트워크 인터페이스 등에서 실시간 로그와 패킷 데이터를 수집하고, jNetPcap 라이브러리를 이용해 저레벨 패킷까지 확보한다. 수집된 원시 데이터는 전처리 단계에서 노이즈를 제거하고, 동일 프로토콜별 해시맵으로 분류된 뒤 MapReduce 작업에 투입된다. Map 단계에서는 각 패킷을 알려진 공격 서명과 매칭하고, Reduce 단계에서는 동일 공격에 대한 빈도와 출현 패턴을 집계한다. 이러한 병렬 처리 구조는 대규모 트래픽(수백만 패킷)에서도 선형에 가까운 확장성을 제공한다는 점이 실험 결과와 일치한다.
계획 모듈에서는 기대 효용(expected utility) 모델을 기반으로 최적의 대응 행동을 선택한다. 공격 집합 E, 대응 행동 집합 A, 결과 집합 O, 비용 C, 시간 T, 성공 확률 P 등을 정의하고, U_E(a_i)=∑_{o∈O}P_a_i(o)·U(o) 식으로 효용을 계산한다. 정규화 과정을 통해 비용·시간·확률을 동일 스케일로 변환하고, 가장 높은 효용을 갖는 행동을 실행한다. 이론적으로는 다중 목표 최적화 문제를 단순화하지만, 실제 적용 시에는 확률과 비용 추정치가 정확하지 않을 경우 의사결정 품질이 저하될 위험이 있다.
실험은 두 가지 시나리오(프라이빗 클라우드 VM, 아마존 퍼블릭 클라우드)에서 수행되었으며, Scapy 기반 DDoS 트래픽과 정상 트래픽을 혼합해 10 MB·130 000패킷, 50 MB·700 000패킷 규모의 데이터셋을 생성하였다. 결과는 탐지 정확도, 응답 지연, 처리량 측면에서 기존 IDS 대비 20‑30% 개선을 보였으며, 특히 응답 지연이 5초 이하로 유지되는 경우가 다수였다. 그러나 논문은 정확도 수치(예: 재현율, 정밀도)와 비교 대상 시스템에 대한 상세한 벤치마크를 제시하지 않아, 성능 우위가 통계적으로 유의미한지 판단하기 어렵다. 또한, 기대 효용 모델에 사용된 파라미터(C, T, P)의 초기값 설정 방법이 구체적이지 않아 재현성에 한계가 있다.
요약하면, 본 연구는 대규모 로그와 패킷을 실시간으로 처리하고, 비용·시간·성공 확률을 종합해 자동 대응을 수행하는 통합 프레임워크를 구현했다는 점에서 실용적 가치를 제공한다. 하지만 파라미터 추정, 정확도 평가, 다중 클라우드 환경에서의 보안 정책 차이 등 실운용 단계에서 해결해야 할 과제가 남아 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기