기업용 머신러닝 성숙도 프레임워크
초록
본 논문은 전통적인 소프트웨어 CMM을 머신러닝 모델 라이프사이클에 적용한 성숙도 프레임워크를 제시한다. 비즈니스 요구 정의, 데이터 요구 전환, 지속적인 정확도·공정성 개선, 도메인 특화 모델 튜닝 등 기업 현장에서 마주하는 실무적 문제들을 해결하기 위한 역할·프로세스·도구를 단계별로 정리하고, 5단계(Initial‑Optimizing) 성숙도 모델을 제안한다.
상세 분석
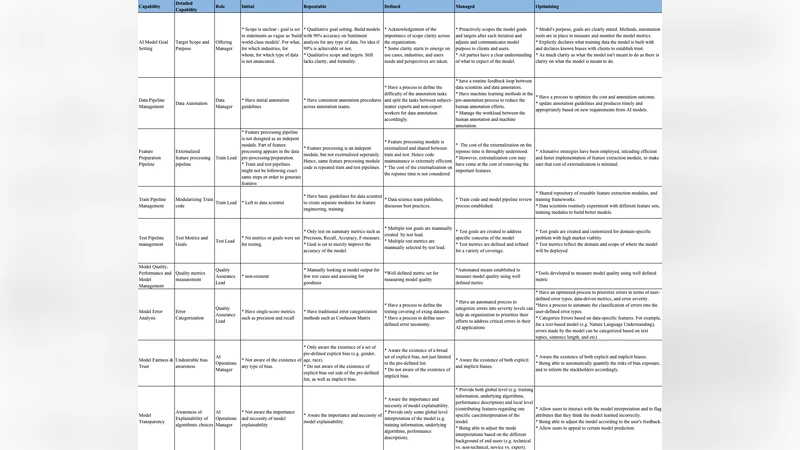
이 논문은 머신러닝 모델을 기업 환경에 도입·운용할 때 필요한 관리 체계를 체계화하려는 시도로서, 기존 학술적 모델링 프로세스와는 차별화된 ‘비즈니스‑데이터‑모델‑운영’ 연계 흐름을 제시한다. 가장 큰 강점은 전통 CMM의 5단계를 그대로 차용하면서도 머신러닝 특유의 데이터 파이프라인, 피처 엔지니어링, 모델 트레이닝·테스트·배포·AI Ops 등 8개의 핵심 단계와 각각에 대응하는 전담 역할(Offering Manager, Content Manager, Data Lead, Training Lead 등)을 구체화한 점이다. 이를 통해 조직이 어느 단계에 머물러 있는지를 진단하고, 다음 단계로 넘어가기 위한 체크리스트와 베스트 프랙티스를 제공한다는 실용성이 돋보인다.
하지만 논문은 몇 가지 한계도 안고 있다. 첫째, 제시된 성숙도 모델이 실제 기업에 적용된 사례 연구가 부족해, 프레임워크의 효과를 경험적으로 검증하기 어렵다. 둘째, ‘공정성·투명성·설명가능성’과 같은 윤리적 요구사항을 다루지만, 이를 정량화하거나 자동화된 검증 메커니즘을 제시하지 않아 실무 적용 시 주관적 판단에 의존할 위험이 있다. 셋째, 기존 빅데이터·AI 거버넌스 모델과의 연계 방안을 간략히 언급했을 뿐, 조직 내 기존 ITSM·DevOps 프로세스와 어떻게 통합될지 구체적인 로드맵이 부족하다.
또한, 역할 정의가 다소 이상화되어 있어, 특히 중소기업에서는 한 사람이 여러 역할을 겸임해야 하는 현실을 충분히 고려하지 않은 듯 보인다. 따라서 프레임워크를 적용하려면 조직 규모·문화에 맞는 역할 재구성이 필요하다. 마지막으로, 성숙도 단계 간 이동을 위한 KPI(예: 모델 정확도 개선율, 데이터 라벨링 품질 점수, 배포 자동화 비율 등)를 명시하지 않아, 조직이 목표 달성 여부를 객관적으로 측정하기 어렵다.
종합적으로, 이 논문은 기업용 ML 운영에 대한 포괄적인 청사진을 제공하지만, 실제 적용을 위한 정량적 지표·사례 연구·조직 맞춤형 가이드가 추가된다면 더욱 설득력 있는 프레임워크가 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기