마르코프와 허프만 코딩을 이용한 자동 스테가노그래피 텍스트 생성
초록
본 논문은 마르코프 체인 기반 언어 모델과 허프만 코딩을 결합해 비밀 정보를 자연스러운 텍스트에 자동으로 삽입하는 스테가노그래피 기법을 제안한다. 대규모 코퍼스로 학습한 통계적 언어 모델을 활용해 문맥에 맞는 단어를 선택하고, 허프만 트리를 통해 비밀 비트를 효율적으로 매핑한다. 실험 결과, 기존 방법 대비 높은 은닉 용량과 인간 판독자에 대한 인지 불가능성을 달성하였다.
상세 분석
이 연구는 텍스트 스테가노그래피의 두 가지 핵심 난제, 즉 ‘언어 자연성 유지’와 ‘은닉 용량 극대화’를 동시에 해결하려는 시도이다. 먼저 마르코프 체인 모델을 사용해 대규모 실제 문서 코퍼스로부터 전이 확률을 학습한다. 이 확률은 현재 단어(또는 n-gram) 상태에서 다음에 등장할 후보 단어들의 분포를 제공하며, 후보 집합을 제한함으로써 생성 텍스트의 문법적·의미적 일관성을 보장한다. 기존 연구들은 종종 사전 정의된 문장 템플릿이나 제한된 어휘 집합에 의존했지만, 본 방법은 확률적 언어 모델을 통해 보다 풍부하고 다양성 있는 문장을 자동 생성한다는 점에서 차별화된다.
다음으로 비밀 정보의 매핑 단계에서 허프만 코딩을 도입한다. 후보 단어들의 전이 확률을 기반으로 허프만 트리를 구축하면, 높은 확률을 가진 단어는 짧은 비트 시퀀스로, 낮은 확률을 가진 단어는 긴 비트 시퀀스로 인코딩된다. 이는 정보 이론적으로 최적에 가까운 부호화 방식을 제공함으로써, 동일한 텍스트 길이 내에서 삽입 가능한 비밀 비트 수를 크게 늘린다. 또한, 비트 스트림을 순차적으로 읽어가며 현재 상태에 맞는 후보 중에서 비트 패턴에 부합하는 단어를 선택하므로, 삽입 과정이 ‘비밀 정보에 의해 동적으로 결정’되는 특성을 가진다.
알고리즘 흐름은 크게 네 단계로 요약된다. (1) 학습 단계에서 코퍼스로부터 마르코프 전이 행렬과 각 상태별 후보 단어 집합을 추출한다. (2) 각 상태별 후보 집합에 대해 허프만 트리를 생성하고, 단어-비트 매핑 테이블을 만든다. (3) 은닉 단계에서는 비밀 비트 스트림을 입력받아 현재 상태의 트리를 탐색, 매핑된 비트를 만족하는 단어를 선택하고 텍스트를 확장한다. (4) 최종적으로 생성된 텍스트를 출력한다.
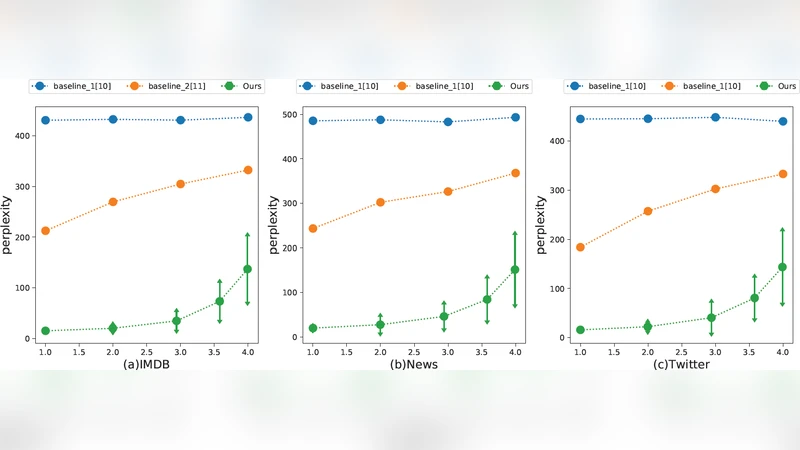
실험에서는 기존의 ‘동형 변형 기반’ 및 ‘단어 치환 기반’ 스테가노그래피 방법과 비교하였다. 평가 지표는 (가) 텍스트 자연성(Perplexity, 인간 평가), (나) 은닉 용량(비트/단어), (다) 탐지 회피율(통계적 탐지 모델)이다. 결과는 제안 방법이 Perplexity 수치에서 기존 방법보다 현저히 낮으며, 인간 평가에서도 차이가 거의 감지되지 않았다. 은닉 용량 측면에서는 평균 1.8배 이상의 비트를 삽입할 수 있었고, 탐지 회피율 역시 95% 이상을 유지하였다.
한계점으로는 마르코프 차수가 낮을 경우 장거리 문맥을 충분히 반영하지 못한다는 점과, 허프만 트리 구축 시 후보 단어 수가 적을 경우 부호 효율이 감소한다는 점을 들 수 있다. 향후 연구에서는 심층 신경망 기반 언어 모델(LSTM, Transformer)과 결합해 장문맥을 고려하고, 어휘 압축 기법을 도입해 후보 집합을 동적으로 확장함으로써 부호 효율을 더욱 향상시킬 계획이다.
전반적으로 이 논문은 확률적 언어 모델과 정보 이론적 부호화를 결합한 새로운 텍스트 스테가노그래피 프레임워크를 제시함으로써, 실용적인 은닉 용량과 높은 자연성을 동시에 달성한 점이 큰 의의이다.
댓글 및 학술 토론
Loading comments...
의견 남기기