뇌전도 신호로부터 파동망을 이용한 음성 재구성 및 음소 선택성 분석
초록
본 연구는 인간의 상측두회(STG)에서 기록된 ECoG 신호를 입력으로, 파라미터 효율성이 높은 WaveNet‑유사 딥러닝 모델을 활용해 원음성 스펙트로그램을 복원한다. 제한된 데이터(두 명의 피험자, 50개 단어)에도 불구하고 WaveNet은 선형 회귀와 ResNet보다 낮은 MSE와 높은 상관계수를 달성했으며, 모델의 임펄스 응답을 분석한 결과 특정 전극이 /ʃ/, /i/, /u:/ 등 개별 음소에 선택적으로 반응함을 확인하였다. 이는 기존 연구가 제시한 pSTG의 음소 인코딩 특성과 일치한다.
상세 분석
이 논문은 두 가지 핵심 질문에 답하고자 한다. 첫째, 제한된 ECoG 데이터셋에서도 과적합 없이 복잡한 비선형 변환을 학습할 수 있는 모델 구조는 무엇인가? 둘째, 학습된 모델의 내부 동작을 통해 STG 전극이 실제로 어떤 음성 특징에 민감한지를 어떻게 추론할 수 있는가? 이를 위해 저자들은 WaveNet의 핵심 아이디어인 팽창(dilated) 컨볼루션과 잔차(residual) 블록을 활용한 파라미터 효율적인 네트워크를 설계하였다. 기본 1‑D 컨볼루션 레이어 뒤에 10개의 잔차 블록을 쌓고, 각 블록은 필터 길이 2, 채널 수 32, 팽창률을 1,2,4,8,16 순으로 두 번 반복한다. 이렇게 하면 1240 ms에 달하는 시간적 수용 영역을 로그‑스케일로 커버하면서 파라미터 수는 약 50만 개에 머문다. 파라미터 효율성은 작은 데이터셋에서 과적합을 방지하는 핵심 요소이며, 배치 정규화와 드롭아웃을 추가해 일반화 능력을 강화하였다.
입력 전처리는 고주파(70‑150 Hz) 힐버트-황 변환을 통해 에너지 앙상블을 추출하고 100 Hz로 다운샘플링한 뒤, 64채널(전극) 형태로 모델에 제공한다. 출력은 32채널(주파수 대역) 스펙트로그램이며, 이는 128‑대역 필터뱅크를 로그‑스케일로 압축한 뒤 32로 재샘플링한 것이다. 모델은 회귀 손실(MSE)로 학습되며, k‑폴드 교차검증(k=3,4)으로 일반화 성능을 평가한다.
비교 대상으로는 동일한 수용 영역을 갖는 1‑D 선형 회귀(단일 컨볼루션)와 8개의 잔차 블록을 가진 ResNet을 사용하였다. 결과는 WaveNet이 S1 데이터셋에서 MSE 0.68, CC 0.65, S2 데이터셋에서 MSE 0.69, CC 0.71을 기록해 두 비교 모델을 모두 앞섰음을 보여준다. 파라미터 수는 ResNet(132 K)보다 많지만, 과적합 없이 높은 성능을 유지한 점은 모델 설계의 효율성을 입증한다.
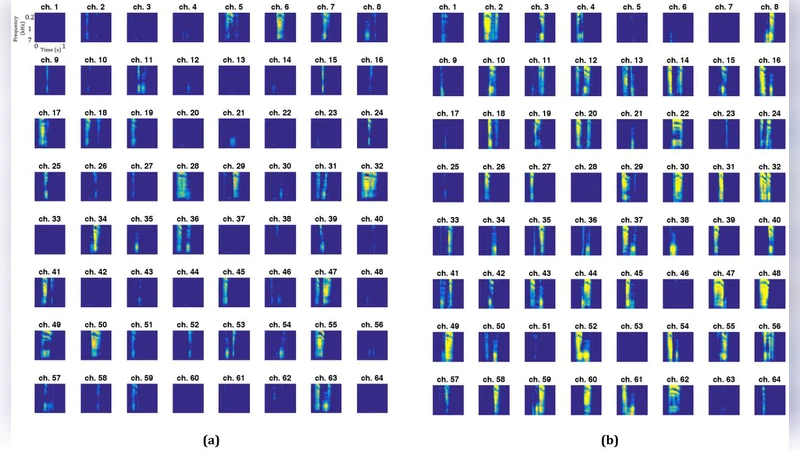
특히 저자들은 학습된 모델에 전극별 임펄스 입력을 주입해 “임펄스 응답”을 시각화하였다. 임펄스는 500‑600 ms 구간에 최대값을 갖는 단일 샘플이며, 이를 통해 모델이 해당 전극에 대해 어떤 스펙트로그램 패턴을 생성하는지 확인했다. 분석 결과, 특정 전극은 /ʃ/, /i/, /u:/ 등 개별 음소에 대응하는 스펙트럼을 생성했으며, 이는 기존 pSTG가 음소 클러스터에 선택적으로 반응한다는 보고와 일치한다. 이러한 발견은 딥러닝 모델이 뇌의 음성 처리 메커니즘을 해석하는 도구로 활용될 수 있음을 시사한다.
한계점으로는 데이터 양이 극히 제한적이며, 단어 반복 횟수가 적어 전극 간 변동성을 충분히 통계적으로 검증하기 어렵다는 점이다. 또한 스펙트로그램을 역변환한 음성은 일부 단어에서만 intelligible했으며, 전반적인 음성 품질 향상을 위해 더 큰 데이터셋과 고해상도 모델이 필요하다. 그럼에도 불구하고, 파라미터 효율적인 WaveNet 구조가 작은 뇌신호 데이터에서도 의미 있는 음성 재구성을 가능하게 했다는 점은 뇌‑컴퓨터 인터페이스(BCI) 분야에 중요한 전진을 의미한다.
댓글 및 학술 토론
Loading comments...
의견 남기기