키워드 마스크 기반 화자 선택 빔포밍
키워드 구간을 이용해 DNN으로 키워드와 배경음 마스크를 추정하고, 이를 기반으로 MVDR 빔포머를 설계해 이후 명령어를 향상시킨다. 일본어 데이터셋에서 SDR 향상과 문자 오류율(CER) 감소를 입증하였다.
저자: Yusuke Kida, Dung Tran, Motoi Omachi
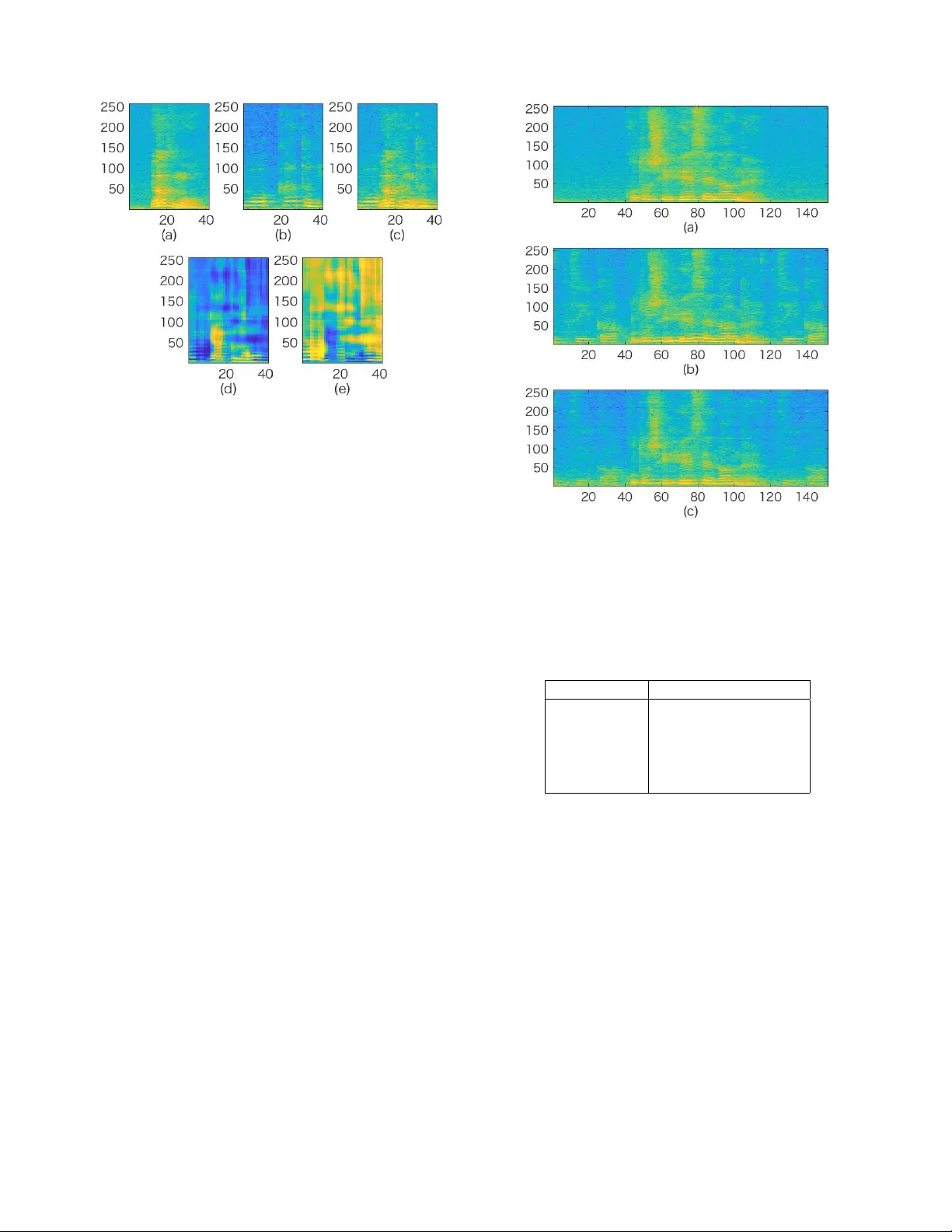
본 연구는 스마트 스피커와 같은 음성 인식 장치가 배경 대화나 텔레비전 소음 등 복합적인 잡음 환경에서도 목표 화자의 명령을 정확히 인식하도록 하는 새로운 방법을 제안한다. 핵심 아이디어는 “wake‑up keyword”가 등장하는 순간을 활용해, 해당 키워드 구간에서 목표 화자의 공간 정보를 추정하고, 이를 바탕으로 다채널 빔포밍을 수행하는 것이다.
먼저, 4채널 마이크 어레이로 녹음된 혼합 신호를 입력으로 하는 DNN 기반 마스크 추정기를 설계한다. 입력 특징은 256 차원의 magnitude 스펙트럼에 앞뒤 10프레임씩 총 20프레임의 컨텍스트를 결합해 5 376 차원으로 만든 뒤, 3개의 1 024 노드 완전 연결층을 거쳐 두 개의 마스크(키워드 마스크와 비키워드 마스크)를 출력한다. 출력은 sigmoid 함수를 사용해 0~1 사이의 확률값으로 제한한다. 학습 목표는 이상적인 이진 마스크(IBM)를 교차 엔트로피 손실로 근사하는 것이며, SGD와 0.2 dropout을 적용해 50 epoch 동안 최적화한다.
학습 데이터는 35명의 화자에게서 수집한 1 660개의 키워드 발화와 25명의 화자에게서 수집한 1 400개의 배경 발화를 각각 독립적으로 녹음한 뒤, 평균 SNR 3.2 dB, 표준편차 3.4 dB인 116 200개의 혼합 데이터를 생성해 구성하였다. 키워드는 일본어 3음절 단어(평균 길이 0.7 s)이며, 각 화자는 1~3 m 거리에서 다양한 각도로 마이크 어레이를 향해 발화한다.
키워드 구간이 검출되면, 해당 구간의 신호에 DNN 마스크를 적용해 키워드와 비키워드(배경) 신호를 각각 분리한다. 이후, 각 채널의 magnitude 스펙트럼과 비키워드 마스크를 이용해 잡음 공분산 행렬 R_nn을 계산하고, 키워드 마스크와 비키워드 마스크를 이용해 스피커 스티어링 벡터 v를 추정한다. v는 키워드 공분산 행렬 R_kk의 최대 고유벡터로 정의된다. 이렇게 얻어진 R_nn과 v를 이용해 최소 분산 무왜곡 응답(MVDR) 빔포머 필터 γ를 구하고, γ를 전체 명령어 구간에 고정 적용한다. 즉, 빔포머는 키워드 구간에서 한 번만 계산되고 이후 구간에서는 업데이트되지 않는다.
신호 수준 평가에서는 시뮬레이션 셋(sim‑set)에서 추정된 키워드 마스크(m_k)와 비키워드 마스크(m_n)의 SDRi 평균값이 각각 4.9 dB와 3.1 dB였으며, 이상적인 IBM을 사용했을 때는 각각 11.1 dB와 10.8 dB로 상한선이 존재함을 확인했다. 마스크가 고주파 영역에서 일부 누락되는 현상이 관찰되었으며, 이는 SDRi 차이의 주요 원인으로 분석된다.
ASR 실험에서는 1 800시간 규모의 DNN‑HMM acoustic 모델(5개의 1 024‑노드 완전 연결층)과 1.6 M 어휘를 가진 3‑gram 언어 모델을 사용했다. 평가 데이터는 (1) 시뮬레이션 셋(1 200 utterance)과 (2) 실제 텔레비전 소음이 섞인 실험 셋(4 396 utterance) 두 가지이며, 각각에 대해 문자 오류율(CER)과 상대 오류 감소율(RERR)을 측정했다. 결과는 다음과 같다.
- Mixed(원본 혼합 신호) 대비 Proposed(제안 방법)에서는 CER이 약 30 % 이상 감소하였다.
- BeamformIt(기존 다채널 빔포밍)보다 제안 방법이 유의미하게 낮은 CER를 기록하였다.
- Oracle(IBM) 실험은 상한선으로, 제안 방법이 아직 완전하지 않지만 실용적인 수준임을 보여준다.
이러한 결과는 키워드 구간만으로도 목표 화자의 공간 정보를 충분히 추정할 수 있음을 증명한다. 또한, 사전에 화자별 클린 음성을 녹음할 필요가 없으며, 키워드만 발화하면 누구든지 적용 가능한 장점이 있다. 따라서 개인 비서 시스템, 스마트 홈 디바이스 등에서 화자 식별 없이도 배경 잡음에 강인한 음성 인식을 구현할 수 있다.
향후 연구에서는 마스크 추정 정확도를 높이기 위한 고주파 보강, 키워드 검출 오류에 대한 강인성 강화, 그리고 실시간 구현을 위한 경량화 모델 설계 등이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기