실시간 정보 활용 심층 강화학습 기반 녹색 보안 게임
초록
본 논문은 실시간 발자국 정보와 양측의 즉각적인 행동 반응을 고려한 새로운 녹색 보안 게임 모델(GSG‑I)을 제안하고, 이를 해결하기 위해 이중 오라클과 정책 공간 응답 오라클(PSRO) 위에 딥 Q‑네트워크를 결합한 DeDOL 알고리즘을 설계하였다. 실험을 통해 작은 규모에서는 기존 CFR 기반 방법과 동등한 성능을, 대규모에서는 현존 베이스라인보다 우수한 방어 전략을 도출함을 보였다.
상세 분석
이 논문은 기존 녹색 보안 게임(Green Security Games, GSG)이 현장에서 흔히 발생하는 실시간 정보—예를 들어 포획자(레인저)의 발자국, 카메라 트랩 혹은 드론이 제공하는 위치 데이터—를 전혀 반영하지 못한다는 근본적인 한계를 짚어낸다. 이를 보완하기 위해 저자들은 GSG‑I라는 확장 게임 모델을 정의한다. GSG‑I는 격자형 환경을 기반으로 두 플레이어(수비자와 공격자)가 동시에 움직이며, 각 턴마다 서로의 현재 셀에 남긴 발자국만을 관찰할 수 있는 부분관찰(partial‑observability) 구조를 갖는다. 수비자는 제한된 패트롤 자원을 가지고 이동·정지·공격 도구(함정) 제거 행동을 선택하고, 공격자는 이동과 동시에 함정을 배치하거나 배치하지 않을지를 결정한다. 각 셀마다 함정이 성공적으로 작동할 확률 Pᵢⱼ이 사전에 정의되어 있어, 수비자는 함정을 사전에 제거하거나 공격자를 직접 체포함으로써 보상을 얻고, 실패 시 음의 보상을 받는다. 게임은 최대 T턴까지 진행되며, 양측 모두 무제한 메모리를 보유해 과거 관찰을 누적할 수 있다. 이러한 설계는 실제 보호 구역에서 발생하는 ‘발자국 추적 → 경로 수정’ 루프를 정량적으로 모델링한다는 점에서 혁신적이다.
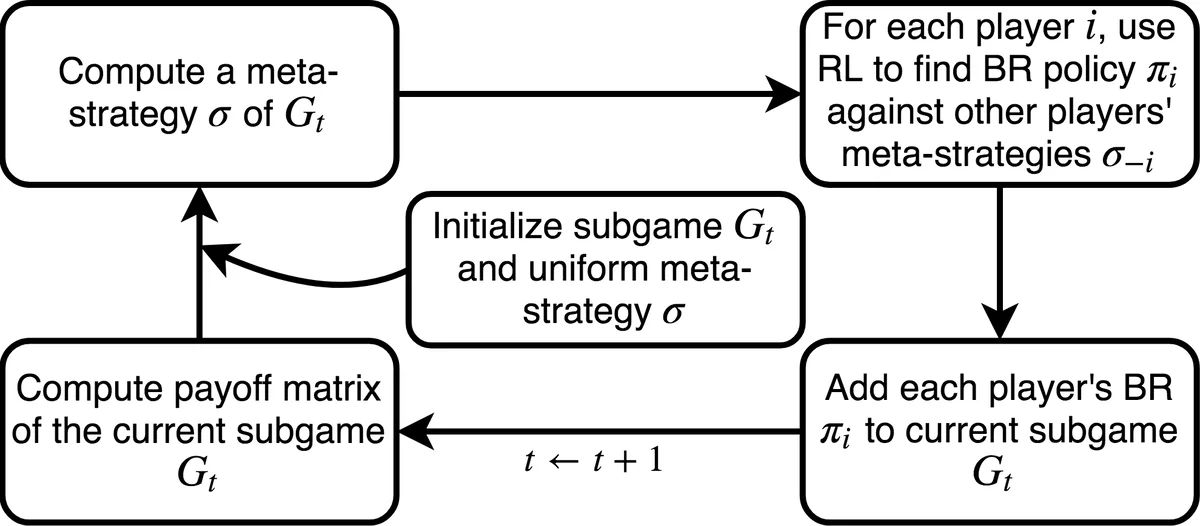
해결 방법으로 제시된 DeDOL은 두 단계의 핵심 아이디어를 결합한다. 첫째, 이중 오라클(Double Oracle, DO) 프레임워크를 차용해 현재 제한된 전략 집합에 대해 내시 균형(Nash Equilibrium)을 계산하고, 각 플레이어의 최적 반응(best response)을 새롭게 추가한다. 둘째, 정책 공간 응답 오라클(PSRO) 개념을 도입해 순수 전략 대신 딥 Q‑네트워크(DQN)로 파라미터화된 정책을 사용한다. 즉, 각 플레이어의 베스트 응답을 구할 때 전통적인 완전 탐색이 아니라 강화학습 에이전트를 훈련시켜 근사한다. 이를 위해 저자들은 CNN 기반의 상태‑액션 매핑을 설계했으며, 입력 채널은 (1) 공격자 발자국, (2) 수비자 발자국, (3) 현재 위치, (4) 각 셀의 함정 성공 확률, (5) 정규화된 시간 단계 등 총 19개이다. 네트워크는 두 개의 컨볼루션 레이어와 풀링, 그리고 듀얼링 아키텍처를 포함해 Q‑값을 출력한다.
또한 학습 안정성을 위해 Double DQN과 듀얼링 네트워크를 결합하고, 정책 그라디언트 기반 방법에서는 액터‑크리틱 구조와 그래디언트 클리핑을 적용한다. 이러한 설계는 특히 상대가 확률적 혼합 전략을 사용할 때 발생하는 비정상적인 보상 변동성을 완화한다.
DeDOL의 효율성을 높이기 위한 추가적인 공학적 기법도 눈에 띈다. 초기 전략 집합에 도메인 특화 휴리스틱(예: 무작위 워크, 무작위 스위핑)을 포함시켜 초기 수렴 속도를 높이고, 공격자의 진입점별로 로컬 모드(local mode)를 정의해 게임 트리를 분할·병렬화한다. 이는 대규모 격자(예: 15×15 이상)에서 메모리와 연산 비용을 크게 절감한다.
실험 결과는 두 가지 축에서 제시된다. 작은 규모(7×7 격자)에서는 CFR 기반 카운터팩추얼 레그레트(CFR)와 비교해 비슷한 수비자 기대 보상을 얻으며, 최적 전략에 근접함을 확인한다. 대규모(≥11×11)에서는 CFR이 메모리 초과로 실행 불가한 상황에서도 DeDOL은 안정적으로 학습을 진행해 기존 베이스라인(무작위 정책, 단순 휴리스틱)보다 현저히 높은 방어 효율을 달성한다. 특히, 실시간 발자국을 활용한 정책이 ‘발자국을 따라가라’와 같은 직관적 규칙보다 더 높은 성공률을 보이며, 공격자의 움직임을 예측하고 함정을 사전에 차단하는 복합 전략을 학습한다는 점이 강조된다.
이 논문은 (1) 실시간 정보가 포함된 보안 게임 모델링, (2) 딥 강화학습을 이중 오라클에 통합한 새로운 알고리즘 프레임워크, (3) 대규모 불완전 정보 게임에 대한 실용적인 학습·평가 파이프라인을 제시한다는 점에서 학술적·실무적 기여가 크다. 향후 연구는 다중 수비자·다중 공격자 확장, 비정형 센서 데이터(음성, 이미지) 통합, 그리고 실제 보호 구역 데이터에 대한 현장 검증 등을 통해 실용성을 더욱 강화할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기