커널 머신, 딥러닝을 넘어선 단일채널 음성 향상
본 논문은 비부드러운 지수 멱 커널과 고속 반복 알고리즘(EigenPro)을 이용해 마스크 기반 단일채널 음성 향상 문제를 해결한다. 자동 하이퍼파라미터 탐색과 주파수 서브밴드별 커널 모델 학습을 통해 기존 딥 뉴럴 네트워크(DNN) 대비 낮은 MSE와 향상된 STOI·PESQ를 달성하면서 학습 시간도 크게 단축한다.
저자: Like Hui, Siyuan Ma, Mikhail Belkin
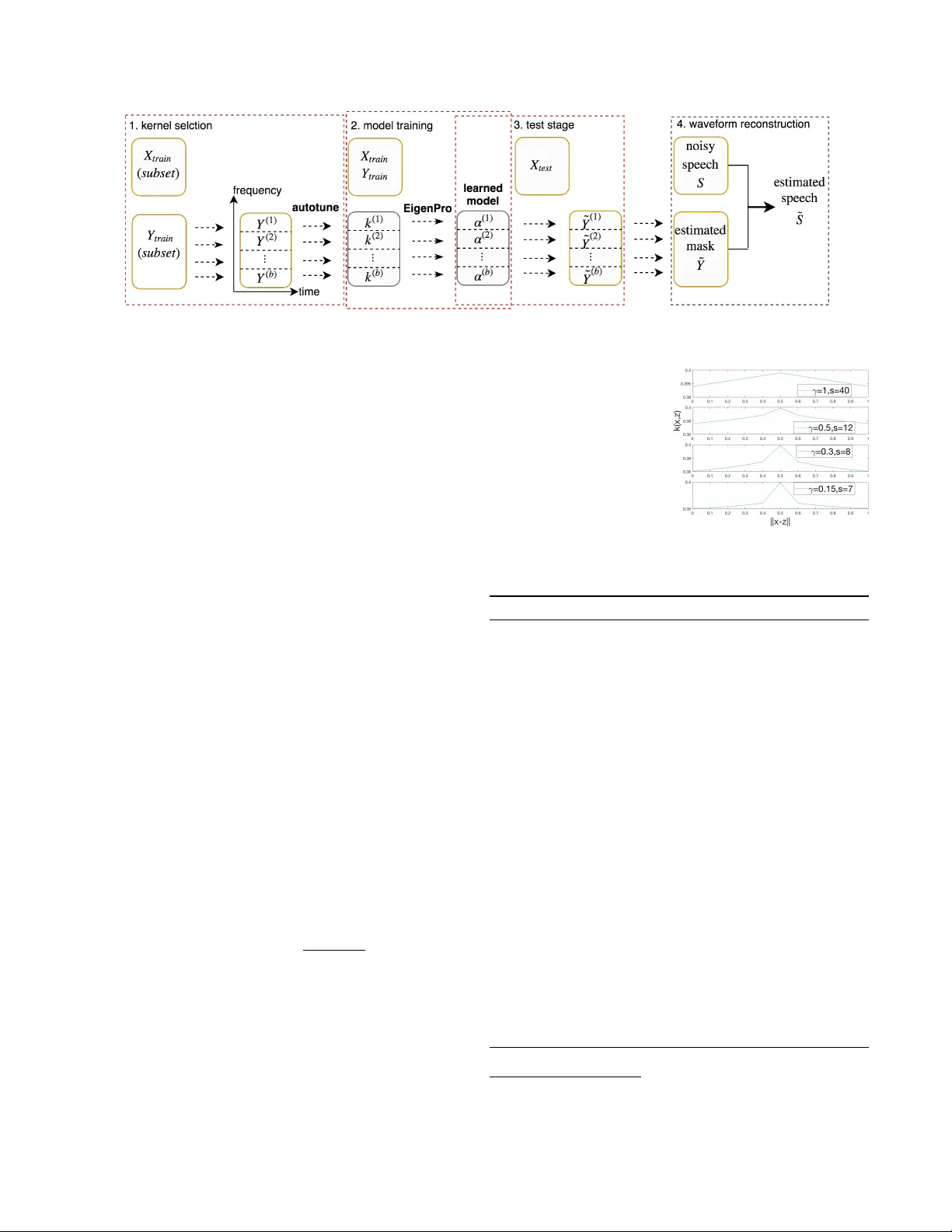
본 논문은 단일채널 음성 향상 문제에 대한 새로운 접근법을 제시한다. 기존 연구에서는 DNN이 다양한 아키텍처(재귀, 합성곱 등)로 우수한 성능을 보였지만, 대규모 데이터에 대한 학습 비용이 크게 요구된다. 저자들은 이러한 한계를 극복하기 위해 ‘대규모 커널 머신’에 초점을 맞추고, 특히 비부드러운 형태의 지수 멱 커널(kγ,σ)과 고속 반복 최적화 기법인 EigenPro를 결합한다.
먼저 커널 머신의 기본 수식(대표성 정리, 커널 회귀)과 지수 멱 커널의 정의를 소개한다. γ=2이면 가우시안, γ=1이면 라플라시안이지만, 저자들은 γ≤1, 특히 γ<1인 경우가 잡음이 많은 음성 스펙트럼에 더 적합함을 실험적으로 확인한다. 이 커널은 기존 문헌에서 거의 사용되지 않은 형태이며, 비부드러움이 모델의 표현력을 높이는 것으로 해석된다.
다음으로 학습 효율성을 위해 EigenPro를 적용한다. EigenPro는 커널 매트릭스의 주요 고유벡터를 사전 계산해 미니배치 SGD에 프리컨디션을 제공함으로써 수천~수만 샘플에서도 수십 회 반복만에 수렴한다. 이는 GPU 메모리와 연산 효율을 크게 향상시킨다.
하이퍼파라미터(γ,σ)의 자동 선택은 알고리즘 1에 상세히 기술된다. 전체 훈련 데이터를 서브샘플링해 교차 검증 손실을 평가하고, 이진 탐색 형태의 라인 서치를 통해 최적 σ를 찾는다. 특히 주파수 채널을 여러 서브밴드(논문에서는 4개)로 나누고, 각 서브밴드마다 독립적인 σ를 탐색한다. 이렇게 하면 각 주파수 대역에서 MSE를 균등하게 낮출 수 있어, STOI·PESQ와 같은 청취 품질 지표와 높은 상관관계를 보인다.
실험은 두 가지 데이터셋을 사용한다. 첫 번째는 TIMIT 기반 회귀 태스크로, IRM(실제 비율 마스크)을 목표로 한다. 5가지 잡음(엔진, 공장, SSN, babble, Oproom)과 -5, 0, 5 dB SNR을 조합해 총 15개의 조건을 만든다. 표 1에서 커널 모델은 모든 조건에서 DNN보다 낮은 MSE를 기록하고, STOI·PESQ에서도 대체로 우수하거나 동등한 성능을 보인다(Factory1 0 dB 제외). 두 번째는 HINT 데이터셋을 이용한 분류 태스크로, IBM(이진 마스크)을 목표로 한다. 여기서는 커널이 babble 잡음에서 DNN보다 높은 정확도와 STOI를 달성하고, SSN에서는 약간 뒤처지지만 전체적으로 비슷한 수준을 유지한다(표 2).
또한 단일 커널(전체 주파수에 하나의 커널)과 서브밴드 적응 커널(4개)의 비교를 수행한다(표 3). 1‑subband 모델은 학습 속도가 빠르고 대부분의 잡음·SNR에서 MSE가 DNN보다 낮지만, STOI가 항상 우수하지는 않다. 특히 SSN 0 dB에서는 전체 MSE는 낮지만 STOI가 DNN에 못 미친다. 4‑subband 모델은 MSE를 더욱 낮추어 STOI·PESQ까지 개선한다. 이는 “주파수 채널별 MSE 감소가 청취 품질 향상에 직접 연결된다”는 중요한 인사이트를 제공한다(그림 2).
시간 복잡도 측면에서는 표 4에 나타난 바와 같이 커널 모델은 1‑subband에서 0.8 분(HINT), 18 분(TIMIT)으로 DNN(3.2 분, 65 분)보다 현저히 빠르며, 4‑subband 모델도 6.6 분, 124 분으로 DNN 대비 약 30‑40 % 적은 학습 시간을 보인다. 이는 EigenPro의 효율적인 GPU 활용과 서브샘플 기반 하이퍼파라미터 탐색 덕분이다.
결론에서는 지수 멱 커널과 EigenPro 기반 학습, 서브밴드 자동 튜닝이 결합돼 대규모 음성 데이터에서도 DNN을 능가하는 성능과 효율성을 달성함을 강조한다. 또한 파라미터 튜닝이 거의 필요 없고, 학습 시간이 짧아 실시간 혹은 저전력 환경에서도 적용 가능함을 시사한다. 향후 연구로는 다른 음성·신호 처리 작업(예: 잡음 억제, 음성 인식 전처리) 및 더 복잡한 마스크(예: 복소수 마스크) 적용이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기