자기주의 언어음향 디코더
본 논문은 텍스트‑음성 변환에서 전통적인 RNN 기반 음향 모델을 대체하기 위해 Transformer 디코더 구조를 활용한 SALAD 모델을 제안한다. 동일한 파라미터 규모에서 약 0.1~0.3 dB 정도의 MCD 상승을 보이지만, CPU 기반 추론 속도가 10배 이상 빨라 모바일 및 임베디드 환경에 적합함을 입증한다.
저자: Santiago Pascual, Antonio Bonafonte, Joan Serr`a
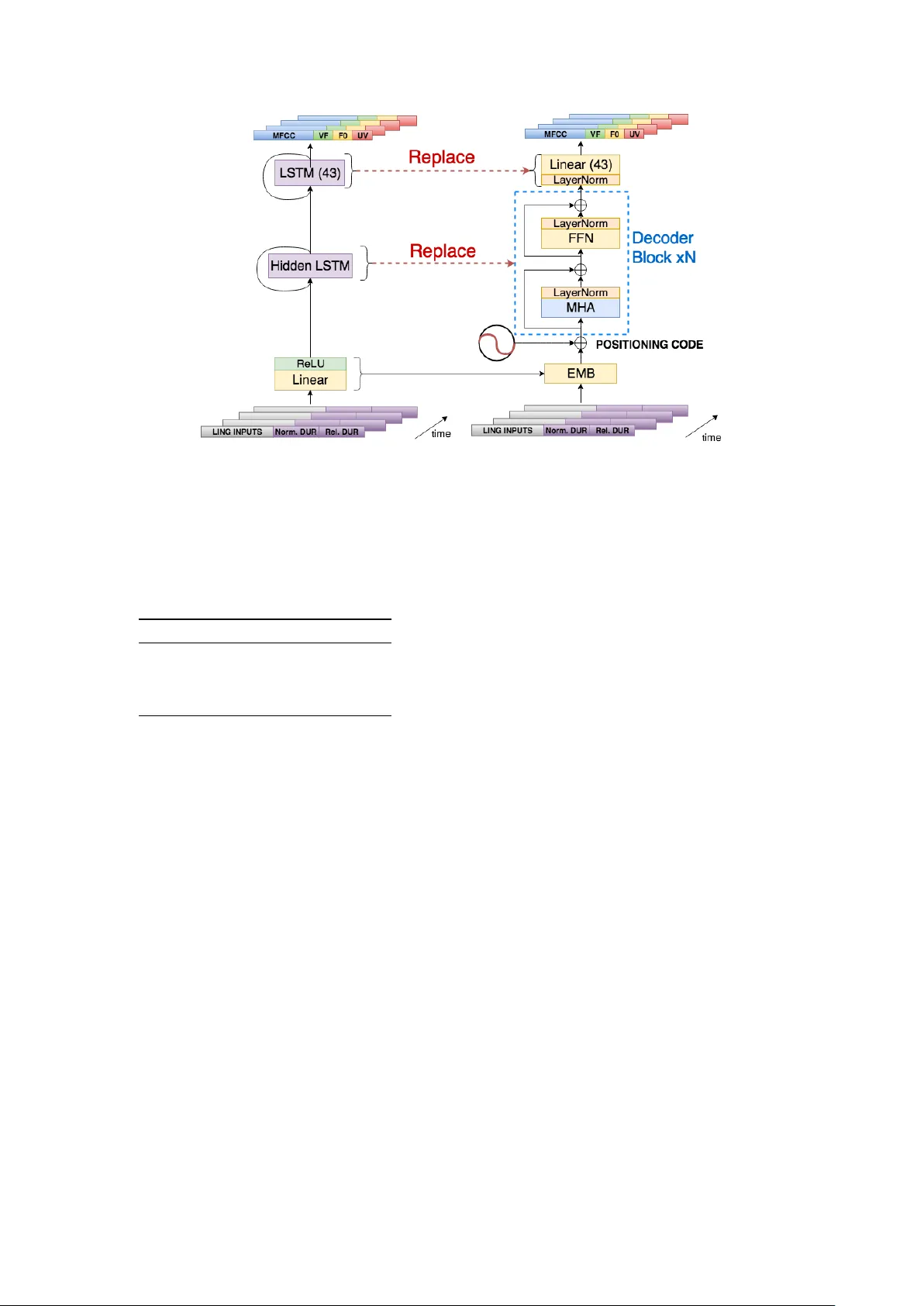
본 논문은 텍스트‑음성 변환(TTS) 시스템의 핵심 과제인 언어‑음향 매핑을 기존의 순환 신경망(RNN, 특히 LSTM) 기반 접근법에서 Transformer 디코더 구조로 전환함으로써 해결하고자 한다. 연구 배경으로는 RNN이 시계열 데이터를 순차적으로 처리해 높은 음성 품질을 제공하지만, 학습 및 추론 시 연산 병목이 발생한다는 점을 들었다. 특히 모바일 및 임베디드 디바이스와 같이 연산 자원이 제한된 환경에서는 이러한 병목이 실시간 합성에 큰 제약이 된다.
이를 극복하기 위해 저자들은 Self‑Attention Linguistic‑Acoustic Decoder(SALAD)라는 모델을 설계했다. SALAD는 기존 MUSA 프레임워크의 두 단계(음소 지속시간 예측, 음향 파라미터 예측) 중 두 번째 단계에 적용된다. 입력 특징은 362 차원의 손수 만든 라벨 벡터(음소 정체성, 품사, 음절 위치 등)이며, 각 음소의 실제 지속시간에 따라 복제되어 364 차원(절대 지속시간, 상대 위치)으로 확장된다. 이 특징은 선형 임베딩 레이어를 통해 H 차원(소형 128, 대형 512)으로 변환되고, 사인·코사인 기반 위치 인코딩이 더해져 시퀀스 내 절대 위치 정보를 제공한다.
SALAD의 핵심은 N개의 트랜스포머 인코더와 유사한 블록으로 구성된 디코더 코어이다. 각 블록은 다중 헤드 자기주의(Multi‑Head Attention)와 피드‑포워드 네트워크(FFN)로 이루어지며, MHA는 h개의 독립적인 주의 헤드를 통해 다양한 시간적 상관관계를 동시에 학습한다. FFN는 차원 d_ff(소형 1024, 대형 2048)로 확장 후 다시 H 차원으로 축소한다. 각 블록 사이와 입력‑출력 사이에 드롭아웃(주의 0.1, FFN 0.5)을 적용해 과적합을 방지한다.
학습은 배치당 32개의 시퀀스를 120 토큰 길이로 구성하고, 상태를 유지하는(stateful) 방식으로 연속성을 보존한다. 최적화는 Transformer 논문에서 제안한 Noam 스케줄을 적용한 Adam 변형을 사용해 초기 학습률을 점진적으로 상승시킨 뒤 역제곱근 스케줄로 감소시킨다. 조기 종료 기준은 검증 세트의 멜 cepstral distortion(MCD)이며, patience는 20 epoch이다.
실험은 스페인어 TCSTAR 코퍼스의 남·여 화자 각각 100분 학습, 15분 검증·15분 테스트 데이터를 사용한다. 음향 출력은 Ahocoder 기반 43 차원(MFCC 40, log‑F0 1, voicing frequency 1, unvoiced‑voiced flag 1)으로 구성된다. 결과는 소형·대형 모델 모두에서 RNN 대비 MCD가 0.1~0.3 dB 상승했으나, F0 RMSE와 UV 정확도는 약간 낮았다. 가장 큰 차이는 추론 속도에 있었으며, CPU 환경에서 SALAD는 최대 5.45 초(35 초 길이 파일)로 머물렀던 반면, 동일 조건의 RNN은 60 초를 초과했다. GPU에서는 두 모델 모두 실시간에 가깝게 동작했지만, 제한된 연산 자원을 가진 디바이스에서는 SALAD가 현저히 유리하다.
추가 분석에서는 SALAD가 평균 피치 예측에서는 RNN에 비해 분산을 충분히 반영하지 못해 평균값에 치우치는 경향을 보였으며, 이는 음성 자연스러움에 미세한 영향을 줄 수 있음을 시사한다. 그러나 전체적인 음질 차이는 인간 청취자 수준에서 크게 체감되지 않을 정도로 작았다.
결론적으로, 자기주의 기반 비순환 구조가 TTS 음향 모델에서 기존 RNN과 거의 동등한 음질을 유지하면서도 추론 효율성을 크게 향상시킬 수 있음을 보여준다. 이는 모바일 어시스턴트, 임베디드 스피커 등 실시간 음성 합성이 요구되는 환경에 직접적인 적용 가능성을 제시한다. 향후 연구에서는 더 정교한 위치 인코딩, 변형된 어텐션 메커니즘, 그리고 멀티스피커 확장 등을 통해 음질 손실을 최소화하면서도 효율성을 유지하는 방안을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기