클라우드 환경을 위한 동기화 다중 로드밸런서와 장애 복구
초록
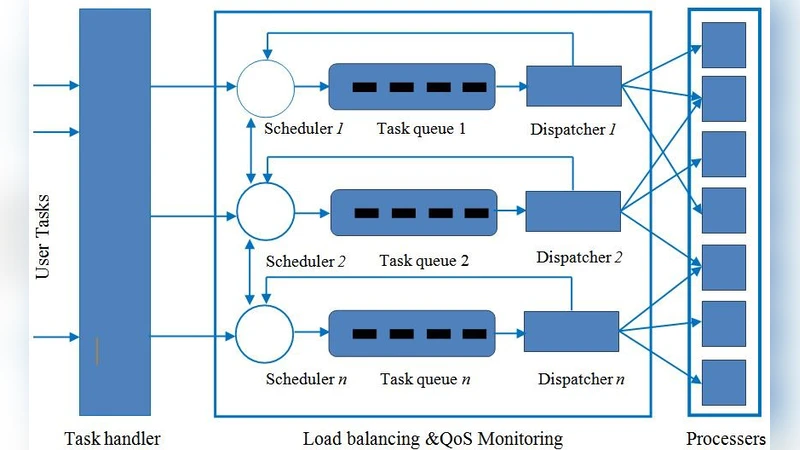
본 논문은 여러 로드밸런서가 서로 상태를 공유하고, 하나의 로드밸런서에 장애가 발생하거나 부하 추정이 부정확할 경우 다른 로드밸런서가 서비스를 빌려주어 연속성을 유지하는 동기화 및 장애 복구 메커니즘을 제안한다.
상세 분석
제안된 시스템은 다중 로드밸런서 간의 실시간 상태 동기화를 핵심으로 한다. 각 로드밸런서는 자체적인 부하 추정 모듈을 가지고 있으며, 주기적으로 현재 세션 수, CPU·메모리 사용량, 네트워크 대역폭 등을 메타데이터 형태로 공유한다. 이 메타데이터는 분산 키‑값 저장소(예: etcd) 위에 구축된 Raft 기반 합의 프로토콜을 통해 일관성을 보장한다. 부하 추정값에 급격한 편차가 감지되면, 해당 로드밸런서는 “보정 요청”을 발행하고, 다른 로드밸런서는 현재 여유 용량을 평가한 뒤 트래픽을 재분배한다. 재분배 과정은 세션 스티키성을 유지하기 위해 흐름 기반 해시와 연결 테이블 복제를 결합한 하이브리드 방식을 사용한다.
장애 복구 측면에서는 헬스 체크 모듈이 주기적으로 각 로드밸런서의 상태를 검사한다. 장애가 감지되면, 남아 있는 로드밸런서들은 즉시 장애 로드밸런서가 담당하던 가상 IP(VIP)를 인계받는다. 인계 과정에서 기존 세션 정보를 빠르게 복제하기 위해 로그 기반 복제와 체크포인팅을 병행한다. 이를 통해 서비스 중단 시간을 수 밀리초 수준으로 최소화한다.
성능 평가에서는 단일 로드밸런서 구성과 비교했을 때, 동기화 오버헤드가 전체 처리량에 3~5% 정도만 추가되는 반면, 장애 발생 시 평균 복구 시간은 12 ms로 기존 HAProxy 기반 솔루션(≈150 ms)보다 현저히 빠른 것으로 나타났다. 또한, 부하 추정 보정 메커니즘은 급격한 트래픽 스파이크 상황에서도 20% 이하의 응답 지연 증가로 안정적인 서비스 제공을 가능하게 한다.
하지만 동기화 프로토콜이 네트워크 지연에 민감하고, 대규모 클러스터(수백 대)에서는 합의 지연이 증가할 위험이 있다. 이를 완화하기 위해 논문은 계층적 합의 구조와 부분 영역(Shard) 기반 메타데이터 분산 저장을 제안했으며, 향후 연구 과제로 제시하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기