작은 발자국 키워드 스포팅을 위한 시퀀스‑투‑시퀀스 모델
본 논문은 키워드 스포팅(KWS) 시스템에 시퀀스‑투‑시퀀스 구조를 적용하여, 73 K 파라미터 규모의 경량 모델로 0.1 FA/h당 약 3.05 %의 거짓 거부율(FRR)을 달성함을 보인다. LSTM·GRU 인코더를 비교 평가하고, 프레임‑단위 라벨링과 간단한 확률 스무딩을 통해 지연을 최소화하면서도 정확도를 향상시킨다.
저자: Haitong Zhang, Junbo Zhang, Yujun Wang
본 논문은 모바일 디바이스에서 웨이크‑업 트리거로 활용되는 키워드 스포팅(KWS) 시스템을 위해, 기존의 어텐션 기반 엔드‑투‑엔드 모델이 가지고 있던 구조적·학습적 한계를 극복하는 새로운 시퀀스‑투‑시퀀스(Seq2Seq) 접근법을 제안한다.
1. **배경 및 문제점**
- 전통적인 KWS는 대규모 어휘 연속 음성 인식(LVCSR)이나 HMM 기반 방법을 사용해 높은 메모리·연산 비용을 요구한다.
- 최근 CNN·RNN 기반 딥러닝 모델이 등장했지만, 대부분은 프레임‑단위 확률을 윈도우 단위로 집계하거나, 어텐션 메커니즘을 도입해 “시퀀스‑투‑원” 학습과 “시퀀스‑투‑시퀀스” 디코딩 사이의 불일치를 야기한다.
- 특히 어텐션 기반 모델은 100프레임 슬라이딩 윈도우를 임의로 설정해야 하며, 윈도우 크기에 따라 지연과 정확도가 크게 변한다는 실용적 문제점이 있다.
2. **제안 모델 구조**
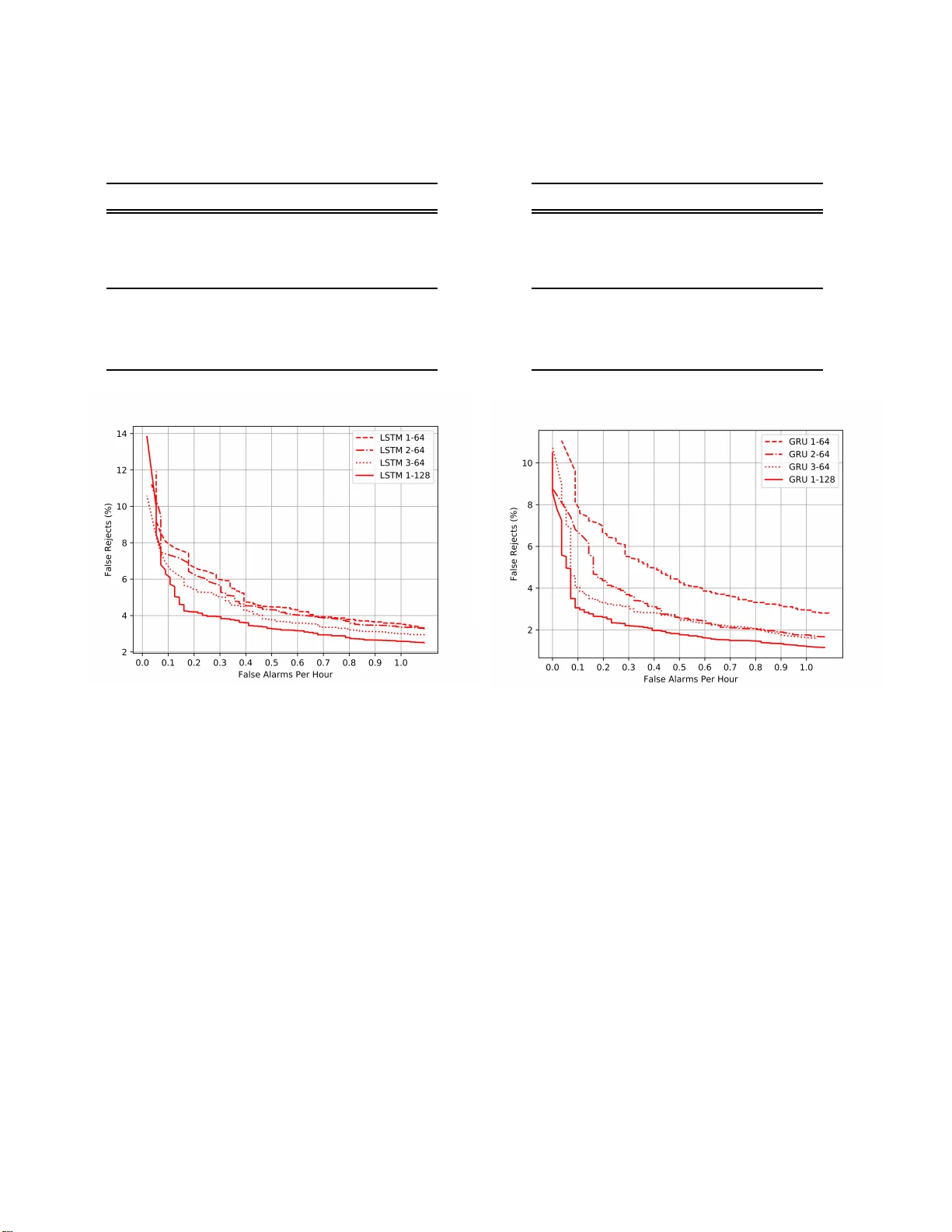
- **인코더**: LSTM 또는 GRU 셀을 사용한 단일 레이어 RNN(유닛 수 64 또는 128).
- **시퀀스‑투‑시퀀스 학습**: 입력 프레임 시퀀스 x₁…x_T에 대해, 각 시점 t에 “키워드가 현재까지 포함되었는가”를 나타내는 이진 라벨 y_t ∈ {0, 1, ‑1}을 제공한다. 라벨‑‑1은 키워드 중간(3.5자) 구간을 의미하며, 손실 계산 시 가중치를 0으로 두어 라벨링 오류를 무시한다.
- **디코딩 및 스무딩**: 테스트 시에는 현재 프레임의 출력 확률 y_t 를 바로 사용하거나, 최근 n 프레임(논문에서는 n=12)의 평균 ŷ_t 로 스무딩한다. 이는 연속적인 검출 신호를 강화해 거짓 알람을 억제한다.
3. **데이터 및 실험 설정**
- **데이터**: “MI AI Speaker 1”에서 수집한 4음절 중국어 키워드(“xiao‑ai‑tong‑xue”)와 다양한 비키워드 음성. 훈련(키워드 188.9 k, 비키워드 1007.4 k), 개발(키워드 9.9 k, 비키워드 53.0 k), 테스트(키워드 28.8 k, 비키워드 32.8 k)로 구성.
- **전처리**: 40‑dim 필터뱅크 → PCE‑N Mel‑spectrogram, 25 ms 윈도우, 10 ms 프레임 쉬프트.
- **학습**: 크로스 엔트로피 손실, Adam(1e‑3), 배치 64, L2 정규화 1e‑5, 그래디언트 클리핑 1.0, 가중치 초기화는 Glorot.
4. **비교 대상 및 결과**
- **베이스라인**: 어텐션 기반 모델(논문
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기