대규모 비라벨 데이터 활용 약한 지도 CRNN 기반 소리 이벤트 탐지
초록
본 논문은 대규모 도메인 내 비라벨 오디오를 활용해 약한 지도 학습 방식으로 강한 라벨을 예측하는 CRNN 모델을 제안한다. 최신 일반 오디오 태깅 모델로 비라벨 데이터에 약한 라벨을 자동 생성하고, 이를 CRNN 기반 강한 라벨 예측기에 투입한다. 앙상블을 통해 노이즈 라벨의 영향을 완화했으며, DCASE 2018 SED 데이터셋에서 F1‑score 21.0%를 달성해 베이스라인 대비 10% 향상하였다.
상세 분석
이 연구는 소리 이벤트 탐지(SED)를 강한 시간 라벨이 없는 상황에서도 실용적으로 적용할 수 있는 방법론을 제시한다는 점에서 의미가 크다. 먼저, 최신 일반 오디오 태깅 모델(예: PANNs, AudioSet 기반)을 이용해 대규모 비라벨 인‑도메인 데이터를 약한 라벨(클래스 존재 여부)으로 변환한다. 이러한 약한 라벨은 원본 데이터에 대한 인간 라벨링 비용을 사실상 0에 가깝게 만든다. 이후, 변환된 약한 라벨과 기존에 강한 라벨이 존재하는 소량의 데이터(프레임 수준 라벨)를 함께 사용해 CRNN(Convolutional Recurrent Neural Network) 구조를 학습한다. CRNN은 2‑D CNN으로 시간‑주파수 특성을 추출하고, 양방향 GRU 혹은 LSTM을 통해 시간적 연속성을 모델링한다.
핵심 기술적 기여는 두 가지이다. 첫째, 약한 라벨이 부여된 비라벨 데이터를 활용해 강한 라벨 예측 모델을 훈련시키는 ‘약한 지도 + 반지도’ 학습 프레임워크이다. 이때, 약한 라벨은 클래스 존재 여부만 제공하므로, 모델은 멀티‑인스턴스 러닝(MIL) 관점에서 각 프레임이 해당 클래스에 속할 확률을 추정한다. 둘째, 라벨 노이즈를 완화하기 위한 앙상블 전략이다. 동일한 구조의 여러 CRNN을 서로 다른 초기화와 데이터 샘플링(부트스트랩)으로 학습시킨 뒤, 예측 결과를 평균하거나 투표 방식으로 결합한다. 이렇게 하면 개별 모델이 과도하게 노이즈 라벨에 과적합되는 위험을 줄이고, 전반적인 일반화 성능을 향상시킨다.
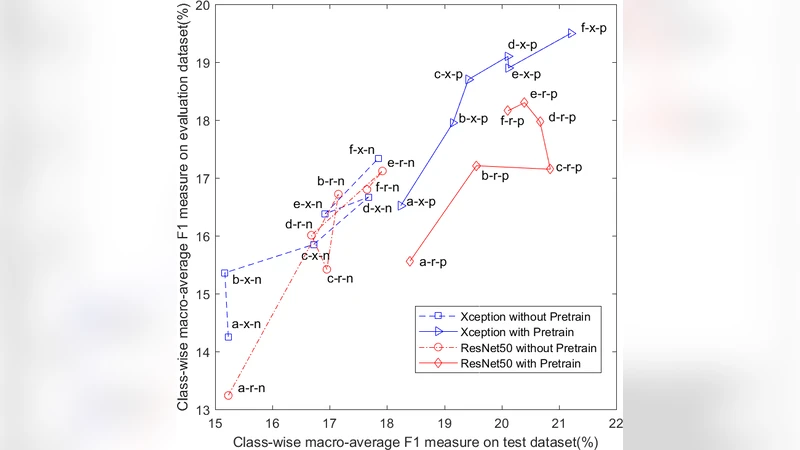
실험 결과는 DCASE 2018 Task 4 SED 데이터셋을 기준으로 한다. 비라벨 데이터를 0%, 25%, 50%, 75% 비율로 추가했을 때, F1‑score는 각각 11.5%, 15.8%, 18.9%, 21.0%로 점진적으로 상승한다. 이는 비라벨 데이터가 충분히 많을 경우, 약한 라벨만으로도 강한 라벨 학습에 유의미한 보조 정보를 제공한다는 것을 입증한다. 또한, 앙상블을 적용했을 때 단일 모델 대비 평균 1.2%p의 F1‑score 향상이 관찰되었다.
이 논문의 한계는 라벨 예측에 사용된 오디오 태깅 모델 자체가 아직 완전하지 않으며, 특히 희귀 이벤트에 대한 약한 라벨 정확도가 낮을 경우 전체 시스템 성능이 크게 저하될 수 있다는 점이다. 또한, 비라벨 데이터의 도메인 적합성(예: 녹음 환경, 소리 종류)이 중요함을 시사하지만, 도메인 불일치 상황에 대한 정량적 분석은 부족하다. 향후 연구에서는 라벨 노이즈를 직접 모델링하는 손실 함수(예: 정규화된 크로스 엔트로피, 라벨 스무딩)와 도메인 적응 기법을 결합해 더욱 견고한 SED 시스템을 구축할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기