향상된 하이브리드 CTC 어텐션 모델로 말인식 정확도 최고 달성
본 논문은 기존 하이브리드 CTC‑Attention 구조에 새로운 CTC 디코더 전용 BiLSTM 층을 추가하고, 서브워드 기반 디코딩을 위한 어텐션 스무딩 기법을 적용한다. encoder 깊이를 늘리고 α(CTC‑Loss 가중치)를 낮게 설정함으로써 학습 수렴 속도와 정렬 정확성을 동시에 향상시켰으며, LibriSpeech test‑clean에서 LM 없이 4.43 %, RNN‑LM 적용 시 3.34 %의 WER를 기록했다.
저자: Zhe Yuan, Zhuoran Lyu, Jiwei Li
본 논문은 최근 엔드‑투‑엔드 음성 인식 분야에서 주목받고 있는 하이브리드 CTC‑Attention 모델을 기반으로, 구조적 개선과 학습 최적화를 통해 성능 한계를 뛰어넘는 방법을 제시한다. 먼저, 기존 모델은 공유 인코더 뒤에 CTC와 어텐션 디코더가 동시에 연결돼 CTC‑Loss의 가중치 α가 작아지면 CTC 디코더의 학습이 충분히 이루어지지 않는 단점이 있었다. 이를 보완하기 위해 저자들은 인코더 최상위 층과 CTC 디코더 사이에 전용 BiLSTM 층을 삽입하였다. 이 층은 CTC‑branch 전용 특징을 추출해 CTC 손실이 작더라도 충분한 그래디언트를 제공함으로써 정렬 정확성을 유지한다.
다음으로, 서브워드 단위(BPE 5,000개)를 사용함에 따라 더 넓은 문맥 정보가 필요함을 인식하고, 어텐션 스코어를 시그모이드 함수로 정규화한 뒤 소프트맥스로 재계산하는 어텐션 스무딩 기법을 도입하였다. 기존 위치 기반 어텐션은 스코어가 급격히 집중돼 서브워드 디코딩 시 중요한 주변 정보를 놓치기 쉬웠지만, 스무딩을 통해 가중치 분포를 완만하게 만들어 장기 의존성을 효과적으로 포착한다.
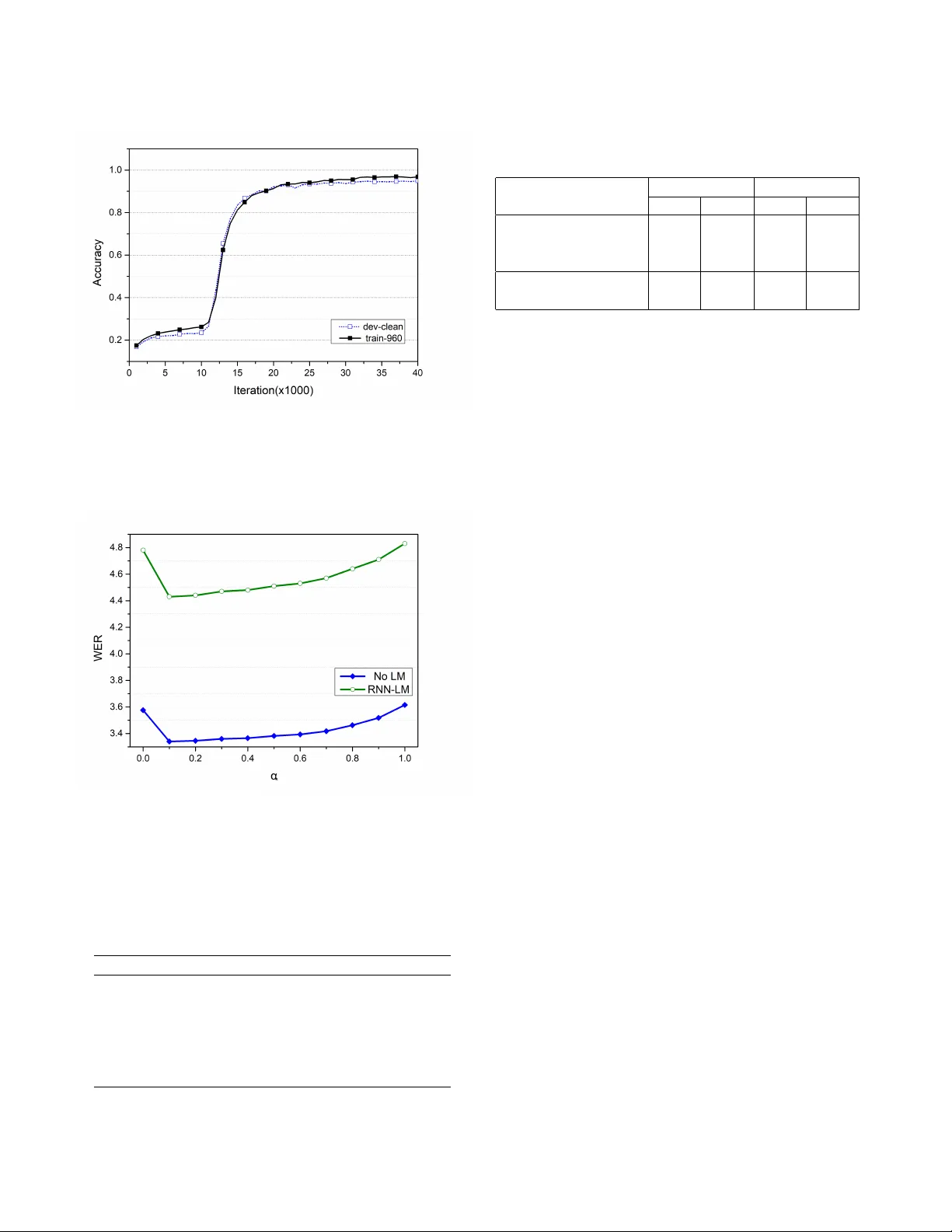
실험 설정은 LibriSpeech 데이터셋을 사용했으며, 80차원 Mel‑filterbank 특징을 3배속 변형(0.9×, 1.0×, 1.1×)과 함께 4‑layer CNN + 7‑layer BiLSTM(양방향 1024 셀) 인코더로 구성하였다. 디코더는 CTC‑branch에 1‑layer BiLSTM, 어텐션‑branch에 2‑layer LSTM(1024 셀)으로 설계되었고, AdaDelta와 L2 정규화, 그래디언트 클리핑을 적용해 학습 안정성을 확보했다. 또한, 2‑layer LSTM 기반 RNN‑LM(1536 셀)을 별도 학습시켜 디코딩 단계에서 빔 서치(beam size 20)와 결합하였다.
성능 평가 결과, 인코더 레이어를 5→7까지 늘리고 CTC‑BiLSTM을 추가했을 때 WER가 지속적으로 감소했으며, 최종적으로 LM 없이 4.43 %, RNN‑LM 적용 시 3.34 %의 WER를 달성했다. 이는 동일 조건에서 보고된 Deep Speech 2, ESPnet, I‑Attention 등 기존 최첨단 모델보다 월등히 낮은 수치이며, 특히 LM 없이도 4.43 %라는 결과는 하이브리드 구조 자체의 강력함을 입증한다. α값 실험에서는 0.1이 최적으로, CTC가 초기 정렬을 돕고 어텐션 디코더가 주된 인식 역할을 수행하도록 설계된 것이 효과적임을 확인했다.
결론적으로, CTC‑branch 전용 BiLSTM 삽입과 어텐션 스무딩은 하이브리드 CTC‑Attention 모델의 정렬 정확도와 문맥 활용 능력을 크게 향상시켰으며, 이러한 구조적·학습적 개선이 엔드‑투‑엔드 음성 인식 시스템의 성능 한계를 확장할 수 있음을 보여준다. 향후 연구에서는 CTC‑branch를 별도 미세조정하거나, 다국어(예: 중국어) 적용을 통해 다중 음소·다중 의미 문제를 해결하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기