피라미드형 FSMN과 LFMMI를 활용한 고성능 음성 인식 모델
본 논문은 기존 DFSMN에 피라미드형 메모리 구조와 앞단에 residual CNN을 결합한 pFSMN을 제안한다. LF‑MMI와 CE를 공동 학습시키고, RNN‑LM으로 재점수를 적용해 Librispeech에서 2.97 %·SWBD‑300에서 10.03 %의 WER를 달성하였다.
저자: Xuerui Yang, Jiwei Li, Xi Zhou
본 논문은 대규모 음성 인식 시스템에서 피드포워드 기반 모델의 장점과 한계를 동시에 고려한 새로운 아키텍처를 제시한다. 기존 Deep Feedforward Sequential Memory Network(DFSMN)는 메모리 블록을 통해 장기 의존성을 모델링했지만, 모든 층이 동일한 컨텍스트 길이를 사용함으로써 파라미터 중복과 효율성 저하가 발생한다. 이를 해결하기 위해 저자들은 피라미드형 메모리 구조(pyramidal‑FSMN, 이하 pFSMN)를 설계하였다. pFSMN에서는 하위 층이 짧은 시간 창(예: ±4 프레임)을, 상위 층이 점진적으로 넓은 창(예: ±20 프레임)을 학습하도록 메모리 블록의 길이와 스트라이드를 층마다 다르게 설정한다. 이렇게 하면 초기 층은 음소 수준의 미세 정보를, 상위 층은 의미·구문 수준의 장기 정보를 추출하게 된다. 또한, 메모리 길이가 변하는 경우에만 스킵 연결을 적용해 그래디언트 흐름을 원활히 하고, 불필요한 스킵을 제거해 연산량을 절감한다.
전처리 단계에서는 6‑layer residual CNN을 도입한다. 입력 MFCC + i‑vector를 2‑D 형태로 재구성해 시간‑주파수 축에 컨볼루션을 수행하고, 짝수 층마다 서브샘플링(Stride 2)을 적용한다. 이는 이미지 처리 기법을 음성 특징에 적용한 것으로, 잡음에 강인하고 고차원적인 표현을 얻는다. 각 CNN 층은 3×3 또는 5×5 커널을 사용하며, 커널 크기가 큰 5×5가 전반적으로 성능 향상에 기여한다는 실험 결과가 제시된다.
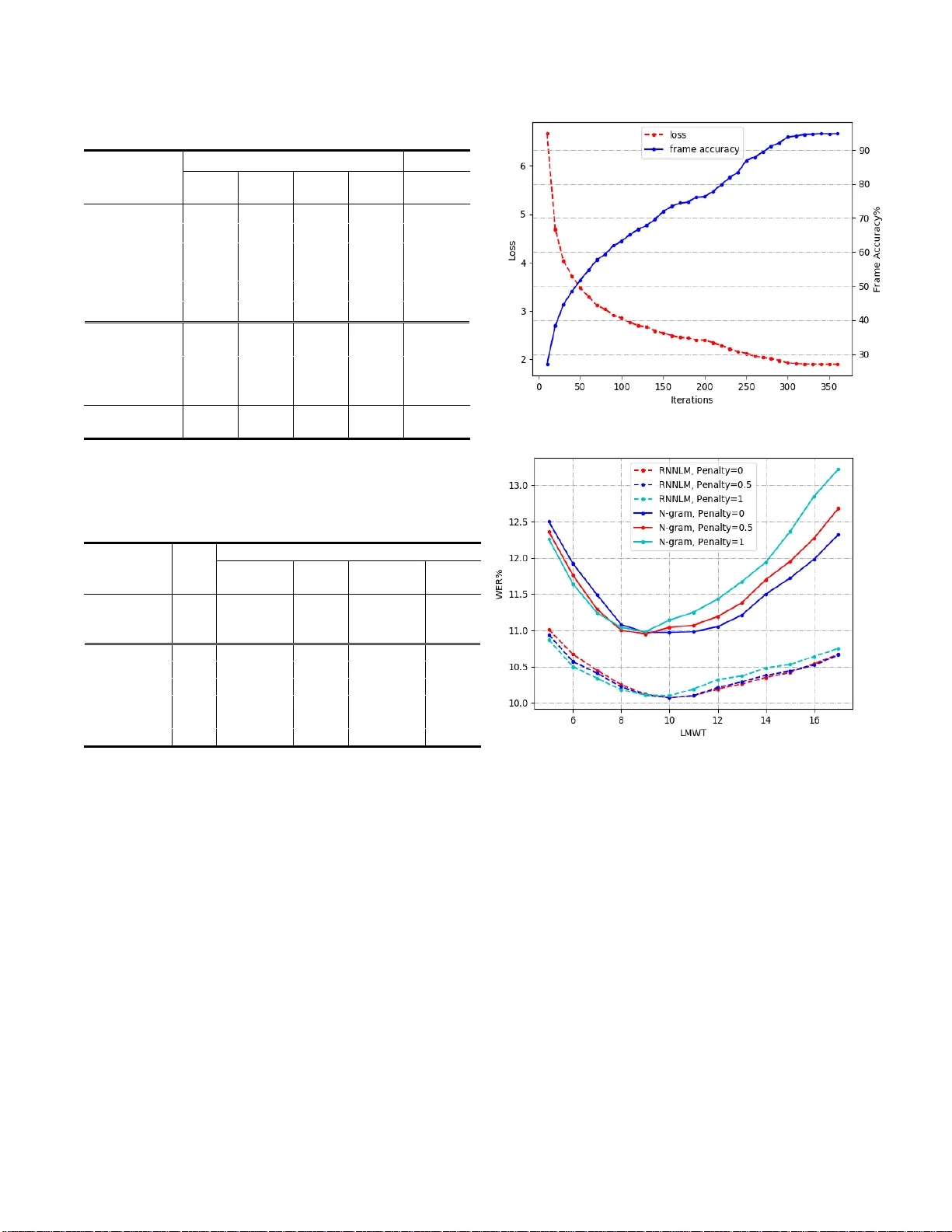
학습 목표는 LF‑MMI와 CE 손실을 가중합하는 다중 목표 최적화이다. CE 손실은 모델이 과도하게 LF‑MMI에 의존해 과적합되는 것을 방지하는 정규화 역할을 하며, LF‑MMI는 시퀀스 레벨의 판별력을 제공한다. 두 손실의 가중치는 λ로 표기되며, 실험에서는 λ≈0.1~0.2가 최적임을 확인했다. LF‑MMI는 lattice‑free 방식으로, 사전 학습된 CE 모델의 라티스를 필요로 하지 않는다. 대신 CTC‑형태의 2‑state left‑to‑right HMM 토폴로지를 사용해 4‑gram 전화 언어 모델과 결합한 forward‑backward 연산을 수행한다. 이 방식은 계산 효율성을 크게 높이며, 기존 CE‑기반 학습 대비 WER를 현저히 낮춘다.
언어 모델 측면에서는 전통적인 4‑gram N‑gram LM을 기본 디코딩에 사용하고, 이후 5‑layer TDNN‑LSTM RNN‑LM으로 n‑best 후보를 재점수한다. TDNN은 현재 프레임과 과거 여러 프레임을 병합해 시간적 컨텍스트를 확장하고, LSTM은 장기 의존성을 보강한다. RNN‑LM 재점수는 평균 1 % 이상의 WER 절감 효과를 보였지만, 디코딩 속도는 감소하는 트레이드오프가 존재한다.
실험 설정은 다음과 같다. 300 시간 Switchboard(SWBD‑300)와 1000 시간 Librispeech 두 코퍼스를 사용했으며, 40‑dim MFCC와 100‑dim i‑vector를 특징으로 채택했다. 3‑fold 스피드 변형(0.9×/1.0×/1.1×)을 적용해 데이터 다양성을 높였고, Kaldi 툴킷을 기반으로 HMM‑GMM 정렬을 사전 준비했다. pFSMN 블록은 10개로 구성되며, 각 블록은 블록‑합 레이어, 선형 레이어, ReLU 레이어(차원 1536→256→256)로 이루어진다. 메모리 블록의 시간 길이와 스트라이드는 4~20, 1~2 범위로 설정했으며, 전체 파라미터 수는 약 8 M이다.
성능 평가 결과, pFSMN‑Chain 모델은 기존 DFSMN‑Chain 대비 Librispeech test‑clean에서 3.96 %→3.62 %(≈9 % 상대 개선), test‑other에서 10.39 %→8.45 %(≈19 % 개선)를 기록했다. SWBD‑300 train‑dev에서는 11.99 %→10.89 %(≈9 % 개선)이며, BLSTM 기반 모델 대비도 우수했다. RNN‑LM 재점수 후 최종 WER는 Librispeech test‑clean 2.97 %와 SWBD‑300 train‑dev 10.03 %에 도달했다. 추가 실험에서는 5×5 커널, semi‑orthogonal 제약, 다양한 스킵 연결 방식 등을 비교했으며, 피라미드형 메모리 구조가 가장 큰 성능 향상을 가져옴을 확인했다.
결론적으로, 피라미드형 메모리 설계와 residual CNN 전처리, LF‑MMI와 CE 공동 학습, 그리고 RNN‑LM 재점수의 조합이 기존 피드포워드 기반 음성 인식 모델의 한계를 뛰어넘는 고성능 시스템을 구현한다는 점을 입증하였다. 향후 연구에서는 LF‑MMI 기반 end‑to‑end 학습, 더 깊은 피라미드 구조, 그리고 Transformer‑계열 모델과의 융합 등을 통해 추가적인 성능 향상을 모색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기