STFT 스펙트럼 손실을 이용한 고성능 신경 음성 파형 모델
본 논문은 단순 파형 오차 대신 단시간 푸리에 변환(STFT) 스펙트럼을 이용한 손실 함수를 제안한다. 진폭과 위상 모두를 고려한 손실을 정의하고, 이를 가우시안 및 von Mises 분포에 기반한 최대우도 학습으로 해석한다. 또한 복잡한 CNN 대신 단방향 LSTM 기반의 간단한 AR 구조를 사용한 모델을 설계하여, 실험에서 기존 WaveNet 및 전통적인 WORLD 보코더보다 높은 음질을 달성함을 보인다.
저자: Shinji Takaki, Toru Nakashika, Xin Wang
본 논문은 “STFT 스펙트럼 손실을 이용한 고성능 신경 음성 파형 모델”이라는 제목 아래, 기존 파형 기반 신경 음성 합성기의 학습 목표를 재정의하고, 이를 기반으로 새로운 네트워크 구조와 학습 방법을 제시한다.
1. **배경 및 동기**
최근 WaveNet과 그 변형들은 직접 파형을 예측함으로써 뛰어난 음성 합성 품질을 달성했지만, 학습 손실로는 주로 샘플 간 L2 손실이나 카테고리형 분포 기반 교차 엔트로피를 사용한다. 이러한 손실은 시간 도메인 차이만을 반영해 주파수 특성을 충분히 활용하지 못한다는 한계가 있다. 특히, 위상 정보는 인간 청각에서 중요한 역할을 함에도 불구하고 대부분의 손실 함수에서 무시된다.
2. **STFT 스펙트럼 손실 정의**
- **STFT 변환**: 입력 파형 y∈ℝᴹ에 대해 행렬 W∈ℂᴸᵀ×ᴹ을 이용해 복소 스펙트럼 Y=W y를 계산한다. 각 프레임 t와 주파수 bin n에 대해 Yₜ,ₙ, 진폭 Aₜ,ₙ=|Yₜ,ₙ|, 위상 θₜ,ₙ=∠Yₜ,ₙ를 구한다.
- **진폭 손실**: E_ampₜ,ₙ = ½(Âₜ,ₙ − Aₜ,ₙ)² 로 정의하고, Wirtinger 미분을 이용해 y에 대한 기울기를 구한다.
- **위상 손실**: 위상이 주기성을 갖는 점을 반영해 E_phₜ,ₙ = ½|1−exp(i(θ̂ₜ,ₙ−θₜ,ₙ))|² = 1−cos(θ̂ₜ,ₙ−θₜ,ₙ) 로 정의한다. 역시 복소 도함수를 사용해 기울기를 구한다.
- **전체 손실**: E_sp = Σₜ,ₙ (E_ampₜ,ₙ + αₜ,ₙ E_phₜ,ₙ) 로, αₜ,ₙ은 가중치이며 세 가지 설정(α=0, α=1, α=vₜ)으로 실험한다.
3. **확률적 해석**
진폭 손실은 평균 μ=Aₜ,ₙ, 분산 σ²=1인 가우시안 로그우도 차이와 동일하고, 위상 손실은 평균 μ=θₜ,ₙ, 집중도 β=1인 von Mises 로그우도 차이와 동일함을 보인다. 따라서 전체 손실은 “진폭은 가우시안, 위상은 von Mises”라는 가정 하에 최대우도 추정(MLE)과 일치한다. 이 해석은 다른 분포(예: Poisson, Exponential, Generalized Cardioid)로 손실을 확장할 수 있는 이론적 기반을 제공한다.
4. **네트워크 아키텍처**
- **입력 네트워크**: 80‑dim 로그멜 스펙트럼을 80‑unit 양방향 LSTM과 5×80 필터 CNN(80개)으로 처리해 시간‑주파수 특징을 추출한다.
- **시간 해상도 맞추기**: 추출된 특징을 복제해 파형 샘플 레이트(16 kHz)와 일치시킨다.
- **출력 네트워크**: 3층 256‑unit 단방향 LSTM을 AR 구조로 배치한다. 이전 400개의 파형 샘플과 현재 특징을 입력으로 받아 다음 샘플을 예측한다.
- **피드백 처리**: 자연 파형을 직접 피드백하는 대신, FFT‑IFFT를 이용해 진폭을 1로 정규화(“amplitude dropout”)하여 모델이 입력 특징에 더 의존하도록 만든다.
5. **실험 설정**
- 데이터: CMU‑ARCTIC 여성 화자(slt) 1,032개 훈련, 50개 테스트, 16 kHz, 16‑bit PCM.
- STFT 파라미터: 프레임 길이 400, 프레임 쉬프트 1, FFT 크기 512.
- 학습: Adam optimizer, 100 k 업데이트, 미니배치당 15 s 파형.
- 비교 대상: 기존 WaveNet(80‑dim 로그멜 → 1024‑mu‑law), 전통적 WORLD 보코더, 그리고 제안 모델 4가지(손실 종류별).
6. **결과**
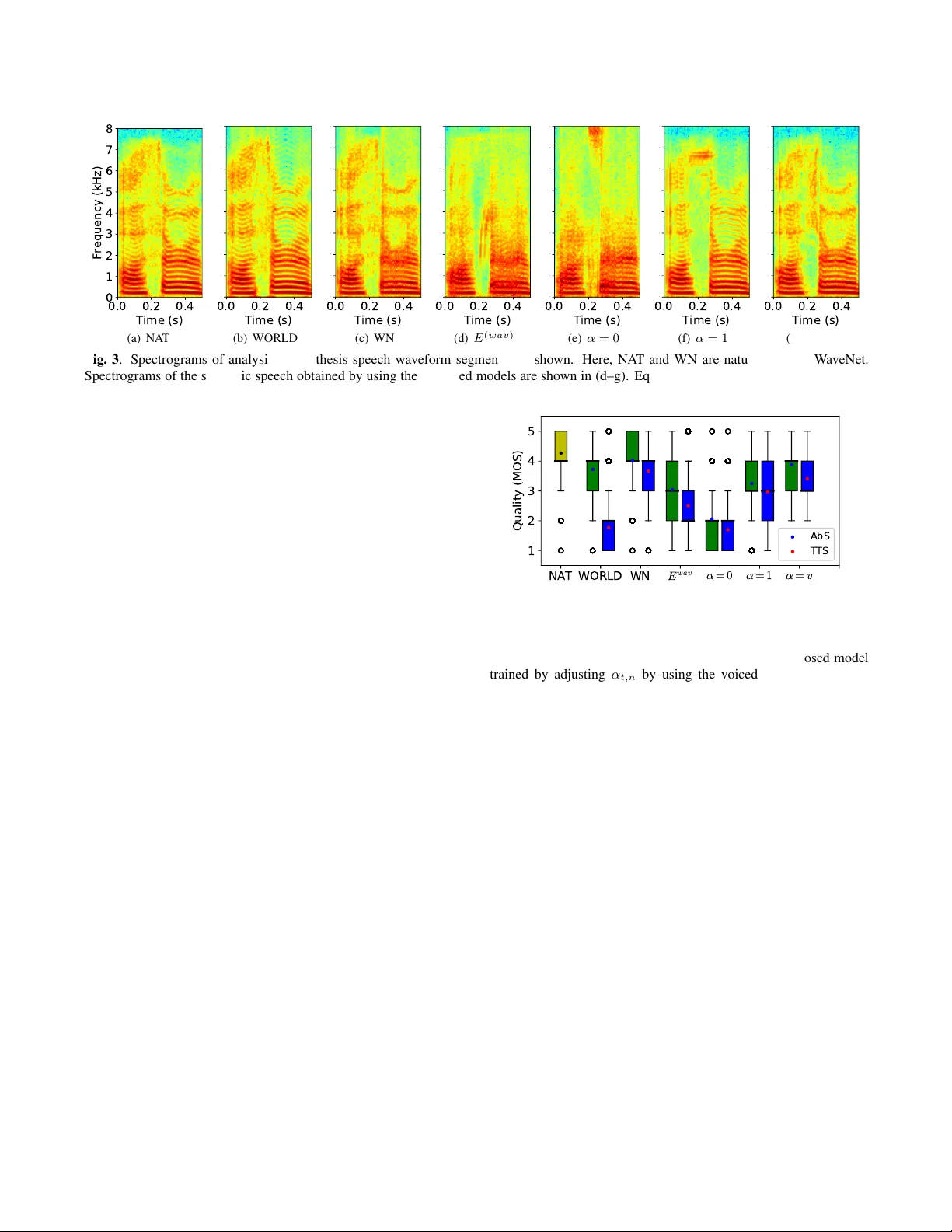
- **스펙트로그램**: α=0(진폭만) 모델은 고주파 노이즈와 비음성 구간에서 인공적인 진폭 스파이크를 보였으며, α=1(진폭+위상) 모델은 무음 구간에서 7 kHz 대역에 과도한 진폭을 나타냈다. α=v(voiced/unvoiced 마스크) 모델은 이러한 아티팩트를 크게 감소시켜 자연스러운 스펙트로그램을 얻었다.
- **주관적 MOS**: 158명 청취자가 5점 척도로 평가했으며, 위상 손실을 포함한 모델이 모든 변형 및 기존 WaveNet, WORLD보다 통계적으로 유의미하게 높은 점수를 기록했다. 특히, TTS 환경에서도 제안 모델은 음성 합성 품질이 안정적이었다.
7. **의의 및 향후 과제**
- STFT 기반 진폭·위상 손실이 파형 모델의 주파수 특성을 효과적으로 학습하도록 돕고, 위상 정보가 음성 자연스러움에 핵심적임을 실증했다.
- LSTM 기반 AR 구조가 복잡한 dilated CNN 없이도 경쟁력 있는 품질을 제공함을 보여, 실시간 혹은 저전력 디바이스에 적용 가능성을 제시한다.
- 확률적 해석을 바탕으로 손실 함수를 다양한 분포로 확장하거나, 멀티‑스케일 STFT, 복소‑가우시안 혼합 모델 등으로 발전시킬 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기