대규모 데이터 시각화를 위한 분할정복 다목적 최적화 알고리즘 mQAPViz
초록
**
mQAPViz는 다목적 이차 할당 문제(mQAP)를 수학적 모델로 삼아, k‑최근접 이웃 그래프와 부정 샘플링을 활용한 분할정복 전략으로 수백만 개 객체의 2차원 그리드 시각화를 효율적으로 생성한다. 실험 결과는 기존 t‑SNE·LargeVis 대비 경쟁력을 입증한다.
**
상세 분석
**
본 논문은 대규모 데이터 시각화 문제를 다목적 최적화(MOP) 관점에서 재정의하고, 이를 해결하기 위한 새로운 프레임워크인 mQAPViz를 제안한다. 핵심 아이디어는 객체와 그리드 위치 사이의 비용을 다중 흐름(flow)과 거리의 곱으로 정의한 다목적 이차 할당 문제(mQAP)를 활용하는 것이다. mQAP는 전통적인 QAP의 확장으로, k개의 서로 다른 흐름 행렬을 동시에 최소화함으로써 유사 객체는 가까이, 비유사 객체는 멀리 배치되는 Pareto 최적 해 집합을 탐색한다.
대규모 데이터에 직접 QAP를 적용하면 계산 복잡도가 O(n³) 수준으로 급증하므로, 저자는 두 단계의 분할정복 전략을 설계한다. 첫 번째 단계에서는 Random Projection Tree(RPT)를 이용해 초기 k‑NN 그래프를 구축하고, 반복적 이웃 재정제 과정을 통해 O(n) 수준의 근사 그래프를 얻는다. 두 번째 단계에서는 부정 샘플링(negative sampling)을 적용해 전체 그래프에서 일정 비율(pₛ)만을 선택, 각 샘플을 중심으로 50×50 격자 영역을 정의하고 해당 영역에 대한 mQAP 서브 인스턴스를 생성한다.
서브 인스턴스 최적화는 병렬 비동기형 메모틱 알고리즘인 P‑asMoQAP을 사용한다. P‑asMoQAP은 개체군 기반 진화 연산(교배·돌연변이)과 지역 탐색(휴리스틱 개선)을 동시에 수행하며, 각 서브 문제를 독립적으로 해결한 뒤 해 집합을 병합(MergeSolutions)하여 최종 시각화를 만든다.
알고리즘의 효율성은 크게 세 가지 요소에 기인한다. ① RPT 기반 k‑NN 그래프는 고차원 데이터의 저차원 구조를 자동 적응적으로 포착해 O(n log n) 수준의 시간 복잡도를 제공한다. ② 부정 샘플링은 그래프의 희소성을 이용해 서브 문제 수를 크게 감소시켜 메모리와 연산량을 절감한다. ③ P‑asMoQAP의 비동기 병렬 설계는 다중 코어 환경에서 거의 선형 확장성을 보인다.
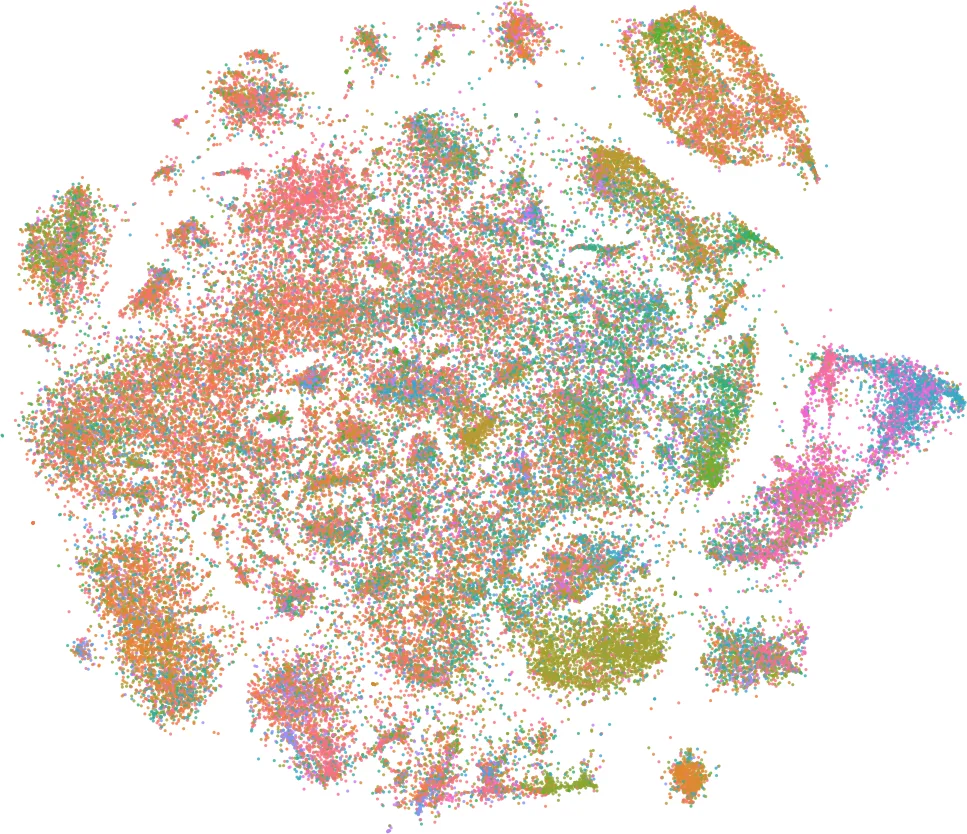
실험에서는 10만~200만 규모의 실세계 데이터셋(이미지, 텍스트, 바이오)과 합성 데이터에 대해 t‑SNE와 LargeVis와 비교하였다. 정량적 평가지표(보존율, KL 발산, 실행 시간)와 정성적 시각적 평가 모두에서 mQAPViz는 비슷하거나 더 나은 클러스터 구조를 유지하면서, 특히 수백만 객체에 대해 수십 분 내에 결과를 도출하는 뛰어난 확장성을 보였다. 다목적 최적화 특성 덕분에 사용자는 흐름 가중치와 거리 가중치를 조절해 특정 도메인 요구에 맞는 시각화 균형을 선택할 수 있다.
본 연구는 시각화 문제를 전통적인 차원 축소가 아닌 이산 최적화로 접근함으로써, 대규모 데이터에 적용 가능한 새로운 패러다임을 제시한다. 향후 작업으로는 흐름 정의의 자동화, 동적 데이터 스트림에 대한 인크리멘털 업데이트, 그리고 3D 혹은 비정형 격자 레이아웃으로의 확장이 제안된다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기