동일 DNN을 연속 연결한 CI DNN으로 잡음 유형 독립성 강화
초록
본 논문은 단일 DNN을 여러 SNR 조건에서 학습시킨 뒤, 동일 모델을 순차적으로 연결해 5 dB씩 SNR을 향상시키는 CI‑DNN 구조를 제안한다. 동일 모듈을 재학습 없이 여러 단계에 걸쳐 적용함으로써 파라미터 수는 최소화하면서도 기존 딥러닝 기반 방법보다 잡음 유형에 대한 일반화가 뛰어나고, 전체 음성 품질·명료도에서도 우수한 성능을 보인다.
상세 분석
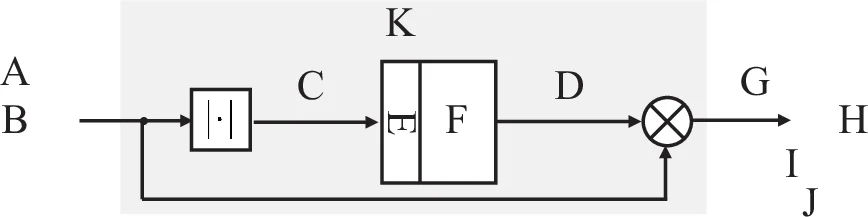
CI‑DNN은 “기본 DNN 모듈” 하나를 설계하고, 이를 23단계로 직렬 연결하는 구조이다. 기본 모듈은 입력 스펙트로그램을 5 dB 향상시키는 목표 SNR을 갖도록 학습되며, 학습 시 −5 dB부터 20 dB까지 6가지 입력 SNR와 각각 5 dB 상승된 출력 SNR(0 dB25 dB)을 모두 사용한다. 이렇게 다중‑SNR 조건을 포함한 손실함수는 모델이 첫 단계뿐 아니라 이후 단계에서도 안정적으로 동작하도록 만든다.
모듈 내부는 5개의 은닉층(1024‑512‑512‑512‑256)과 leaky‑ReLU, 배치 정규화, 0.2 드롭아웃을 적용하고, 입력은 2좌·우 컨텍스트 프레임을 포함한 5×129=645 차원이다. 출력은 마스크 추정값(0~1)으로, sigmoid 활성화와 정규화를 거쳐 실제 스펙트럼에 곱해진다. 각 단계마다 동일한 마스크가 적용되므로 전체 시스템은 “M₁·M₂·…·M_R” 형태의 곱셈으로 표현된다.
연결 단계가 늘어날수록 필요한 컨텍스트 프레임도 증가한다(2단계 → 9프레임, 3단계 → 13프레임). 이는 연산량이 약간 늘어나지만, 파라미터 수는 동일하게 유지된다. 따라서 파라미터 효율성이 크게 향상된다.
실험에서는 Grid 코퍼스와 CHiME‑3의 PED, CAFE, BUS 잡음(보지 않은 BUS) 3종을 사용해 16명(훈련)·4명(테스트) 스피커를 대상으로 평가하였다. 평가 지표는 ΔSNR, PESQ(깨끗한 음성·전체), SSDR, WLAKR, STOI 등 6가지이며, 각각 잡음 억제, 음성 품질, 잡음 왜곡, 인식 가능성을 측정한다.
비교 대상은 전통적인 LSA·SG·WF 가중법과, 동일 파라미터 규모의 “단일 DNN”(1~3단계 규모)이다. 단일 DNN은 깨끗한 타깃(클린)과 잡음 타깃(노이즈) 두 버전으로 학습했으며, 파라미터 수는 CI‑DNN과 거의 동일하거나 더 많았다.
결과는 다음과 같다. 전통 가중법은 저 SNR에서 PESQ(음성) 점수가 높지만, WLAKR가 크게 나와 잡음 왜곡이 심하고 STOI가 낮다. 클린 타깃 단일 DNN은 ΔSNR와 전체 PESQ·STOI에서 우수하지만, SSDR·PESQ(음성)와 WLAKR에서 불균형을 보이며, 특히 저 SNR에서 잡음 품질이 크게 저하된다. 반면, 노이즈 타깃 단일 DNN과 CI‑DNN은 모두 잡음 품질(WLAKR)과 음성 품질(SSDR·PESQ) 사이에 균형을 이루지만, CI‑DNN이 파라미터가 동일하거나 더 적음에도 불구하고 전반적인 성능이 약간 더 우수하다. 특히 보지 않은 BUS 잡음에 대해서는 CI‑DNN이 가장 높은 ΔSNR·STOI·PESQ(전체)를 기록하며, 일반화 능력이 뛰어남을 확인한다.
핵심 인사이트는 “다중‑SNR 학습 + 동일 모듈 직렬 연결”이라는 설계가 모델 복잡도는 낮추면서도 단계별 5 dB 향상을 보장한다는 점이다. 이는 기존의 점진적 학습(P‑DNN)이나 깊은 네트워크와 달리, 재학습 없이 단계 수만 조절해 다양한 억제 요구에 대응할 수 있다. 또한, 동일 모듈을 여러 단계에 재사용함으로써 파라미터 공유가 자연스럽게 발생해 과적합 위험이 감소하고, 보지 않은 잡음에 대한 강인성을 확보한다.
댓글 및 학술 토론
Loading comments...
의견 남기기