멀티태스크 학습을 활용한 리플레이 스푸핑 탐지 시스템
초록
본 논문은 자동 화자 인증(ASV)에서 리플레이 공격을 탐지하기 위해, 리플레이 과정에서 발생하는 ‘리플레이 노이즈’를 별도 클래스로 정의하고, 스푸핑 검출과 동시에 세 종류의 노이즈(재생 장치, 녹음 환경, 녹음 장치) 분류를 수행하는 멀티태스크 딥러닝 모델을 제안한다. ASVspoof2017 데이터셋 실험에서 기존 최고 성능 시스템 대비 평가 셋에서 약 30% 상대적 EER 감소를 달성하였다.
상세 분석
이 연구는 리플레이 공격이 기존 스푸핑 공격보다 탐지 난이도가 높다는 점에 착안한다. 리플레이 공격은 원본 음성에 추가적인 채널 노이즈—재생 장치(P), 녹음 환경(E), 녹음 장치(R)—가 결합되는 과정으로 이루어진다. 논문은 이러한 노이즈를 “리플레이 노이즈”라 명명하고, 이 노이즈가 스푸핑 검출에 유용한 특징을 제공한다는 가설을 세운다.
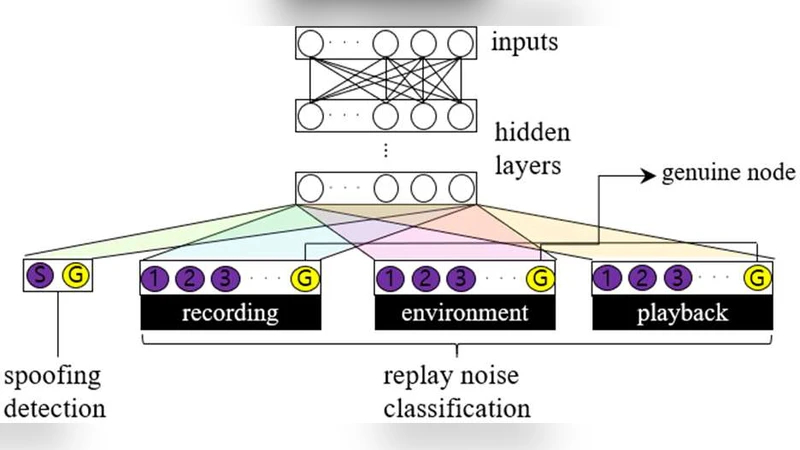
모델 아키텍처는 Light CNN(LCNN) 기반의 전처리 네트워크를 사용한다. LCNN은 Max‑Feature‑Map(MFM) 활성화와 max‑out 구조를 통해 파라미터 수를 줄이고 중요한 스펙트로그램 패턴을 강조한다. 전처리 네트워크 뒤에는 5개의 컨볼루션 블록이 순차적으로 배치되고, 각 블록마다 1×1, 3×3 필터와 MFM이 적용돼 특징 표현을 점진적으로 압축한다. 최종적으로 13×32×16 크기의 특성 맵을 얻은 뒤, dropout(0.7)과 완전 연결층(FC6, FC7)을 거쳐 다중 출력 레이어에 연결한다.
멀티태스크 학습은 총 4개의 태스크를 동시에 최적화한다. (1) 스푸핑 검출(진짜/스푸핑 2 클래스), (2) 재생 장치 분류(8개 장치 + 진짜 1 클래스), (3) 녹음 환경 분류(4개 환경 + 진짜 1 클래스), (4) 녹음 장치 분류(7개 장치 + 진짜 1 클래스)이다. 각 태스크는 동일 가중치의 교차 엔트로피 손실을 사용해 전체 손실을 구성한다. 진짜 클래스를 각 노이즈 분류에 추가함으로써, 모델이 진짜와 스푸핑을 구분하면서도 노이즈 종류별 특성을 학습하도록 유도한다.
학습 데이터는 ASVspoof2017 v1.0의 원본 훈련·개발 세트를 재구성하여 사용한다. 스펙트로그램 입력은 400×257×32 형태이며, 4초 길이의 오디오를 무작위로 추출·복제해 길이 일관성을 확보한다. 전처리 단계에서 평균-분산 정규화를 적용하고, Adam 옵티마이저(learning rate=1e‑3)로 100 epoch 정도 학습한다.
실험 결과는 두 가지 관점에서 평가된다. 첫째, 기존 최고 성능 시스템(Lavrentyev et al., 2017)을 재현한 베이스라인과 비교했을 때, 제안 모델은 검증 셋에서 EER 9.47% → 4.21% (약 55% 절감), 평가 셋에서 13.57% → 9.56% (약 30% 절감)으로 크게 향상된다. 둘째, t‑SNE 시각화를 통해 스푸핑 샘플이 여러 클러스터로 분리되는 현상을 확인했으며, 노이즈 분류 태스크가 추가됨에 따라 진짜와 스푸핑 사이의 경계가 명확해진다. 이는 멀티태스크 학습이 스푸핑 검출에 필요한 판별 정보를 보강한다는 증거다.
한계점으로는 (1) 노이즈 클래스가 사전에 정의된 고정 집합에 의존한다는 점, (2) 평가 셋에 포함되지 않은 새로운 장치·환경에 대한 일반화 성능 검증이 부족하다는 점을 들 수 있다. 향후 연구에서는 노이즈 라벨링을 자동화하거나, 도메인 적응 기법을 도입해 미지의 장치·환경에서도 강인한 탐지를 목표로 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기