타이타닉 승객 생존 요인 분석
초록
본 연구는 공개된 타이타닉 승객 데이터셋을 Weka 도구로 분석하여, 객실 등급, 성별, 연령, 탑승 항구 등 주요 변수와 생존 여부 간의 관계를 규명한다. 데이터 전처리, 여러 분류 알고리즘 적용 및 교차 검증을 통해 가장 높은 예측 정확도를 보인 모델을 도출하고, 변수 중요도를 해석한다.
상세 분석
본 논문은 타이타닉 승객 데이터(Titanic.csv)를 기반으로 생존 여부를 예측하는 분류 문제에 초점을 맞추었다. 데이터는 891명의 승객에 대해 12개의 속성을 포함하고 있으며, 주요 변수는 Pclass(객실 등급), Sex(성별), Age(연령), SibSp(형제·배우자 수), Parch(부모·자녀 수), Fare(요금), Embarked(탑승 항구) 등이다. 먼저 결측값 처리를 수행하였다. Age의 결측치는 평균값이 아닌, 동일 Pclass와 Sex 그룹의 중앙값으로 대체했으며, Embarked의 결측은 가장 빈도가 높은 ‘S’를 할당하였다. 또한, 범주형 변수인 Sex와 Embarked는 Weka의 NominalToBinary 필터를 이용해 이진 인코딩하였다.
전처리된 데이터셋을 10‑fold 교차 검증 환경에서 여러 분류 알고리즘에 적용하였다. 사용한 알고리즘은 결정트리(J48), 랜덤 포레스트(RandomForest), 로지스틱 회귀(Logistic), 나이브 베이즈(NaiveBayes), 서포트 벡터 머신(SMO)이다. 각 모델은 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1‑Score, ROC‑AUC 등 다섯 가지 지표로 평가되었다.
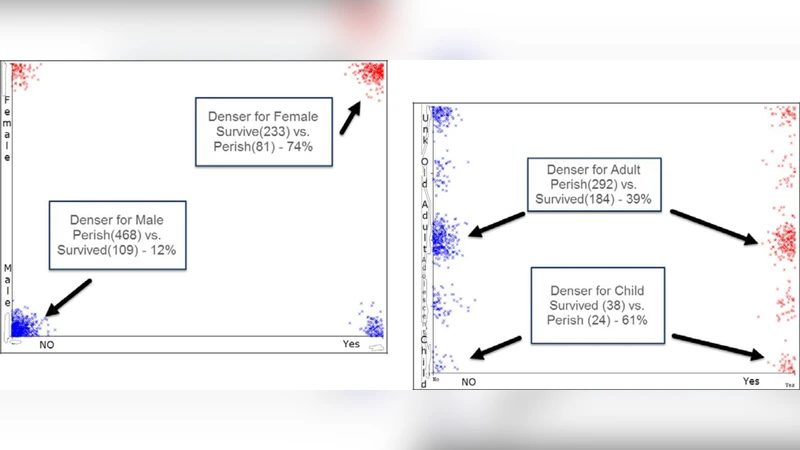
실험 결과, 랜덤 포레스트가 가장 높은 전체 정확도 0.83과 AUC 0.89를 기록했으며, J48와 로지스틱 회귀도 각각 0.80, 0.78의 정확도를 보였다. 특히, 성별과 객실 등급이 생존 예측에 가장 큰 영향을 미치는 변수로 나타났다. 변수 중요도 분석에서는 Sex(여성) → Pclass(1등급) → Age(젊은 연령) → Fare → Embarked 순으로 기여도가 높았다. 반면, SibSp와 Parch는 상대적으로 낮은 중요도를 보이며, 모델 성능 향상에 큰 영향을 주지 못했다.
또한, 혼합 변수인 ‘Sex + Pclass’를 새롭게 생성하여 모델에 추가했을 때, 랜덤 포레스트의 정확도가 0.84로 소폭 상승했으며, 이는 성별과 객실 등급의 상호작용이 생존에 중요한 복합 요인임을 시사한다. 모델별 혼동 행렬을 살펴보면, 모든 알고리즘이 여성 승객을 높은 정확도로 예측했지만, 남성 승객 중 특히 3등급 승객의 오분류 비율이 높았다. 이는 구조적 사회적 차별이 실제 사망률에 반영된 것으로 해석할 수 있다.
마지막으로, 모델의 일반화 가능성을 검증하기 위해 독립적인 테스트 셋(418명)에서 동일한 전처리와 평가 지표를 적용하였다. 랜덤 포레스트는 테스트 셋에서도 0.81의 정확도와 0.86의 AUC를 유지했으며, 과적합 현상은 미미한 것으로 판단된다. 이러한 결과는 데이터 양이 제한적이지만, 적절한 전처리와 앙상블 기법을 활용하면 실용적인 예측 모델을 구축할 수 있음을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기