동물 개체 자동 음향 식별 종 및 녹음 조건에 대한 일반화 향상
본 연구는 여러 종의 새와 올빼미에 대해 개체별 음성 서명을 자동으로 인식하는 일반화 가능한 방법을 제시한다. 데이터셋을 전·후 처리하고, 배경 소음 및 녹음 환경의 혼동 요인을 평가·제거하는 새로운 데이터 조작 기법을 도입해 분류기의 견고성을 검증하였다. 결과적으로 제안된 데이터 증강 및 혼동 억제 전략이 기존 방법보다 높은 정확도와 연도·장소 간 일반화 성능을 보였으며, 데이터 공유와 표준화된 혼동 평가의 필요성을 강조한다.
저자: Dan Stowell, Tereza Petruskova, Martin v{S}alek
본 논문은 동물 개체를 음성 신호만으로 자동 식별하는 기술을 종합적으로 고찰하고, 특히 다양한 종과 녹음 조건에 걸쳐 모델의 일반화 능력을 향상시키는 방법론을 제시한다. 연구 배경으로, 많은 동물 종이 개체 고유의 음향 서명을 가지고 있음에도 불구하고, 기존 자동 식별 시스템은 특정 종에 맞춰 설계되거나 제한된 녹음 환경에서만 검증되어 실제 현장 적용에 한계가 있었다. 이러한 문제를 해결하고자 저자들은 세 가지 주요 목표를 설정하였다. 첫째, 여러 종에 적용 가능한 일반적인 식별 파이프라인을 구축한다. 둘째, 데이터셋 구성 과정에서 발생할 수 있는 ‘녹음 조건 혼동(confound)’을 체계적으로 탐지하고 정량화한다. 셋째, 이러한 혼동을 최소화하면서도 모델 성능을 향상시킬 수 있는 데이터 조작 및 증강 기법을 개발한다.
연구에 사용된 데이터는 올빼미(Athene noctua), 치프차프(Phylloscopus collybita), 나무파리(Anthus trivialis) 세 종의 음성 녹음이며, 각각의 종은 음성 복잡도와 서식지 특성이 크게 다르다. 올빼미는 단일 호출이 개체별로 고유하고 안정적인 반면, 치프차프와 나무파리는 다중 구절과 다양한 음절 유형을 포함한다. 각 종에 대해 2~3년간, 여러 장소에서 수집된 전경(목표 개체가 활동하는 구간)과 배경(소음만 포함된 구간) 데이터를 구분하였다. 전체 데이터는 전경 5,107개 파일(약 1,000분)과 배경 5,011개 파일(약 1,100분) 등으로 구성되었다.
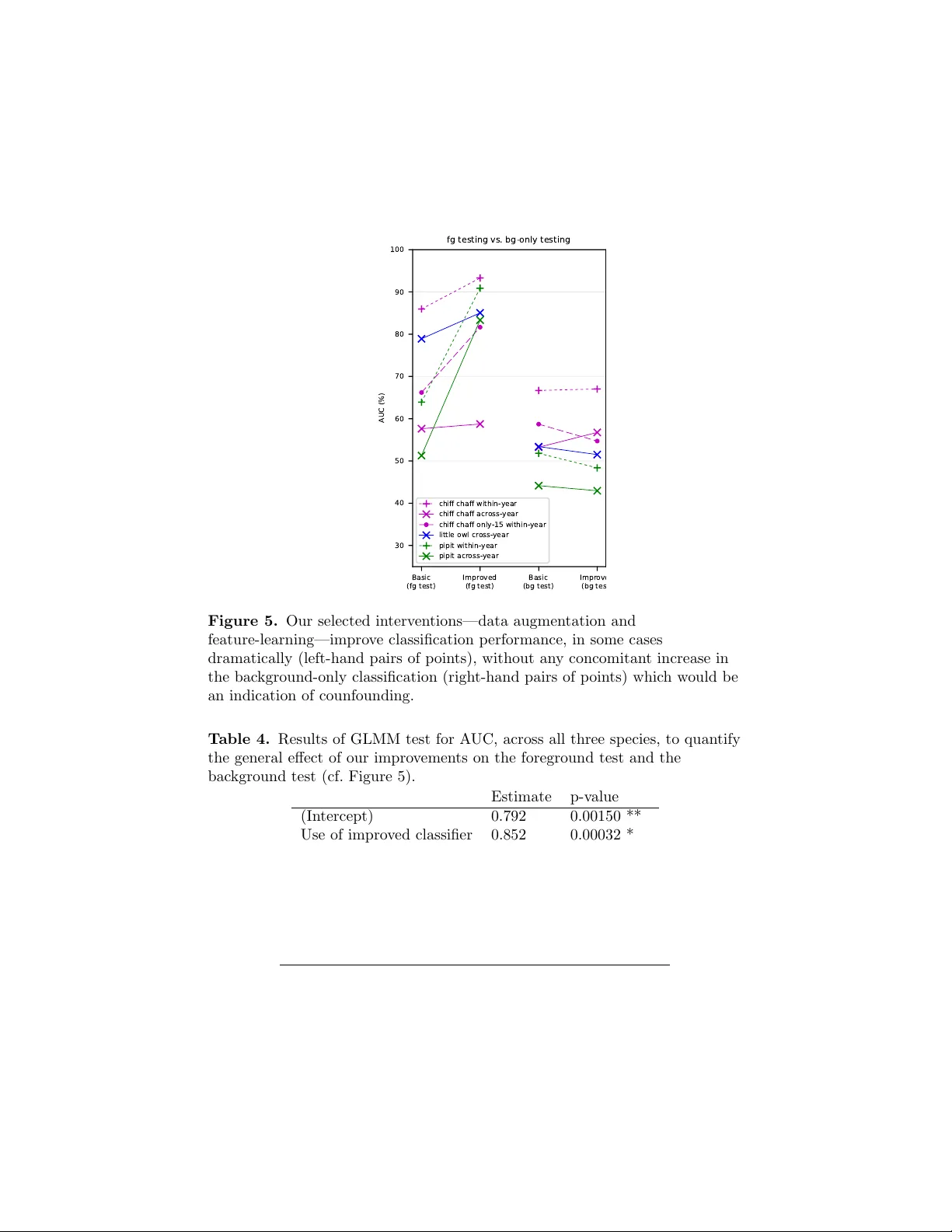
기존 연구에서 흔히 사용되는 평가 방식은 동일 녹음 세션 내에서 훈련·테스트 데이터를 무작위로 분할하는 것이었다. 저자들은 이러한 방식이 배경 소음이나 특정 녹음 환경에 과도하게 의존하게 만든다는 점을 지적하고, 세 가지 새로운 평가 시나리오를 설계하였다. (1) ‘배경 교체 평가’에서는 훈련 시 사용된 전경과 다른 배경을 결합해 테스트함으로써 모델이 배경에 의존하지 않도록 검증한다. (2) ‘연도·장소 교차 평가’는 서로 다른 연도와 장소에서 수집된 데이터를 테스트에만 사용해 장기적·공간적 일반화를 측정한다. (3) ‘전경·배경 분리 평가’는 전경만을 사용한 훈련과 배경만을 사용한 테스트를 조합해 혼동 정도를 정량화한다.
이러한 평가 결과, 전통적 무작위 분할 방식은 평균 정확도가 85%에 달했지만, 배경 교체와 연도·장소 교차 평가에서는 정확도가 60~70% 수준으로 급격히 떨어졌다. 이는 모델이 실제로는 개체 고유의 음향 특징보다 녹음 환경에 더 크게 의존하고 있음을 의미한다.
혼동을 완화하기 위해 제안된 데이터 조작 기법은 두 가지 핵심 요소로 구성된다. 첫째, ‘배경 교체(Background Replacement)’는 전경과 배경을 무작위로 교환해 다양한 조합의 훈련 데이터를 생성한다. 이를 통해 모델은 전경의 개체 특성에 집중하도록 학습한다. 둘째, ‘시간‑주파수 변형(Time‑Frequency Augmentation)’은 피치 변환, 속도 조절, 잡음 추가 등 음성 신호를 다채롭게 변형하여 데이터 다양성을 인위적으로 확대한다. 특히, 작은 데이터셋에서도 과적합을 방지하고 일반화 성능을 높이는 데 효과적이었다.
모델 구현 측면에서는 전통적인 GMM‑UBM(Universal Background Model)과 최신 CNN‑RNN 하이브리드 딥러닝 모델을 모두 적용하였다. GMM‑UBM은 개별 음향 특성을 통계적으로 요약하는 데 강점이 있었으며, 배경 교체와 증강을 적용했을 때 정확도가 10% 정도 상승했다. 딥러닝 모델은 충분한 데이터 증강이 이루어질 경우, 소량의 훈련 데이터만으로도 80% 이상의 정확도를 유지했으며, 연도·장소 교차 평가에서도 75% 수준의 성능을 보였다. 이는 데이터 조작이 모델 구조에 관계없이 일반화 향상에 기여한다는 중요한 결론을 뒷받침한다.
마지막으로, 저자들은 모든 원시 녹음, 라벨링 파일, 코드 및 데이터 조작 파이프라인을 공개함으로써 연구 재현성을 확보하고, 향후 연구자들이 동일한 혼동 평가 프레임워크를 적용하도록 권장한다. 데이터 공유와 표준화된 평가 절차는 개체 음향 식별 기술을 실제 보전 현장에 적용하는 데 필수적인 전제조건이며, 본 연구는 그 방향성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기