사회적 피드백 학습: 의견이 갈라지는 새 메커니즘
초록
본 연구는 의견 양극화를 설명하는 새로운 메커니즘을 제시한다. 개인은 자신의 의견을 표현했을 때 주변으로부터 받는 사회적 반응(지지/비판)을 피드백으로 학습하여 해당 의견에 대한 가치를 재평가한다. 높은 모듈성(군집성)을 가진 연결망에서는 서로 다른 집단이 경쟁적인 의견에 대해 강한 신념을 형성할 수 있으며, 게임 이론의 평형 개념을 연결하여 양극화 안정성에 대한 조건을 분석적으로 규명한다.
상세 분석
이 논문의 핵심 기술적 기여는 ‘사회적 피드백에 의한 강화 학습’이라는 새로운 의견 동역학 메커니즘을 제안하고, 이를 게임 이론의 평형 개념과 연결하여 분석적 틀을 제공한 점에 있다. 기존 모델들이 논증 기반의 합의 과정이나 부정적 영향, 제한된 신뢰(경계 신뢰) 같은 비선형 가정에 의존한 반면, 본 모델은 단순한 보상 기반 학습으로 양극화를 설명한다.
핵심 메커니즘은 다음과 같다: 각 에이전트는 두 가지 대립적 의견(예: 찬성/반대) 중 하나를 표현한다. 이웃 에이전트들의 반응(동의/비동의)은 표현된 의견에 대한 ‘가치 평가’에 영향을 미치는 보상으로 작용한다. 동의는 긍정적 보상으로 해당 의견의 가치를 높이고, 비동이는 부정적 보상으로 가치를 낮춘다. 에이전트는 높은 가치를 가진 의견을 표현할 확률이 높아지는 방식으로 학습한다.
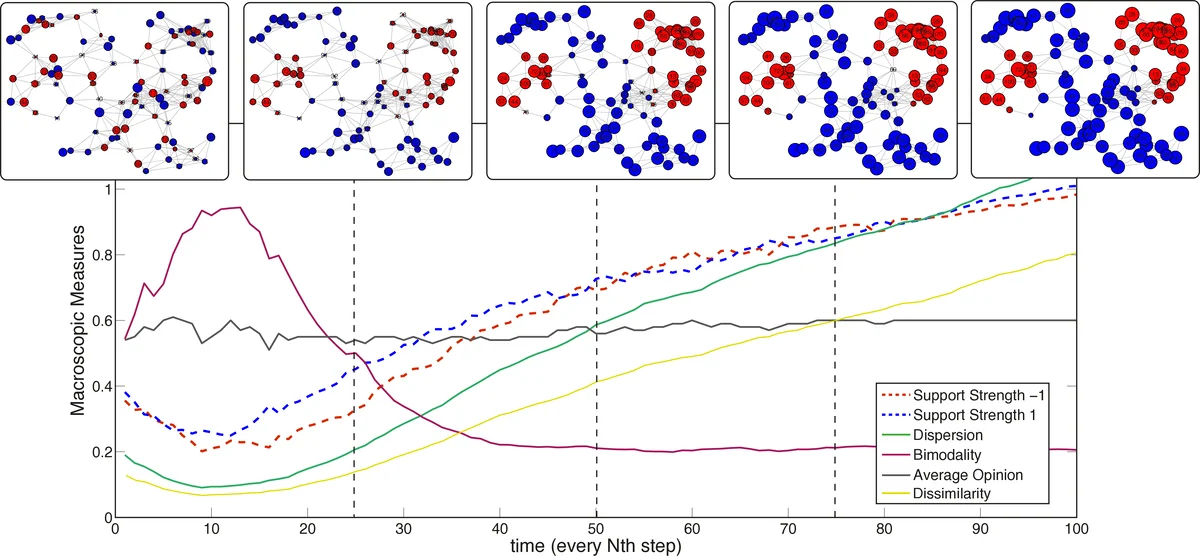
이 과정은 마코프 결정 과정으로 형식화될 수 있으며, 장기적으로 에이전트는 주변 이웃의 평균적 의견에 내재화된 기대 보상에 수렴하는 ‘의견 게임’의 평형에 도달한다. 여기서 게임 이론이 도입된다. 논문은 네트워크에 ‘응집성 있는 하위 그룹’이 존재할 경우, 서로 다른 하위 그룹이 각기 다른 의견 평형에 도달하여 안정적인 양극화가 발생할 수 있음을 보인다. 이는 연결된 네트워크에서도 내부 연결이 밀집한 공동체 사이의 ‘구조적 공백’이 의견의 확산을 차단하는 ‘게이트키핑’ 역할을 하기 때문이다.
수학적 분석을 통해, 군집 내부의 강화 학습은 그룹 양극화를 유발하고(집단 내 의견이 극단으로 이동), 군집 간의 약한 연결은 이러한 극단적 평형이 전체 네트워크로 수렴되는 것을 방해하는 충분조건이 도출되었다. 이 모델은 에이전트 기반 시뮬레이션으로 검증되었으며, 무작위 기하 그래프 등에서 안정적인 공간적 의견 군집이 형성됨을 확인했다.
댓글 및 학술 토론
Loading comments...
의견 남기기