파일 내용과 특성 기반 악성코드 분류 연구
초록
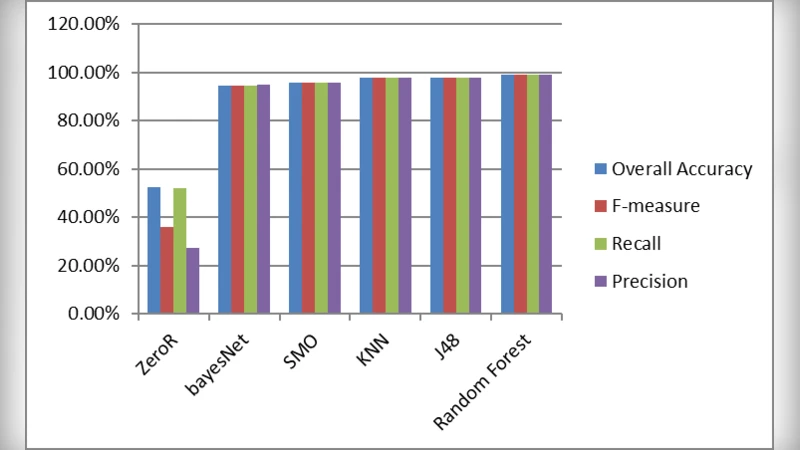
본 논문은 Clamp Integrated 데이터셋(5,210개 샘플)을 활용해 파일 내용과 메타데이터를 기반으로 악성코드를 분류한다. Weka에서 ZeroR, BayesNet, SMO, KNN, J48, Random Forest 여섯 가지 알고리즘을 적용했으며, Random Forest가 99.10%의 최고 정확도를 기록했다. 결과는 랜덤 포레스트가 파일 기반 악성코드 탐지에 효과적임을 시사한다.
상세 분석
이 연구는 악성코드 탐지 분야에서 전통적인 서명 기반 방법의 한계를 보완하기 위해 파일 내부의 정적 특성과 메타 정보를 활용한 머신러닝 접근을 시도한다. 사용된 Clamp Integrated 데이터셋은 5,210개의 인스턴스로 구성돼 있으며, 각 인스턴스는 파일 바이트 시퀀스, 섹션 헤더, 임포트 테이블 등 다양한 정적 특성을 포함한다. 데이터 전처리 단계에서 결측값을 0으로 대체하고, 범주형 특성은 원-핫 인코딩을, 연속형 특성은 Z-스코어 정규화를 적용하였다. 이러한 전처리는 알고리즘 간 비교의 공정성을 확보하는 데 필수적이다.
Weka 환경에서 실험된 여섯 가지 분류기는 각각 다른 학습 편향을 가지고 있다. ZeroR는 클래스 비율만을 반영한 베이스라인으로, 실제 모델 성능을 평가하는 기준점으로 활용되었다. BayesNet는 조건부 독립성을 가정하는 확률 그래프 모델로, 특성 간 상관관계가 약할 경우 강점을 보인다. SMO는 서포트 벡터 머신의 근사 구현으로, 고차원 특성 공간에서 마진을 최대화한다. KNN은 거리 기반 비모수 방법으로, 데이터 밀도가 높은 영역에서 정확도가 떨어질 위험이 있다. J48은 C4.5 기반 결정트리로, 해석 가능성이 높지만 과적합 위험이 존재한다.
실험 결과 Random Forest가 99.0979%라는 압도적인 정확도를 달성했으며, 이는 다수의 결정트리를 앙상블하여 개별 트리의 편향을 감소시키고 분산을 제어한 결과로 해석된다. 또한, 변수 중요도 분석을 통해 파일 헤더 정보와 특정 바이트 패턴이 악성 여부를 판단하는 데 핵심적인 역할을 함을 확인하였다. 그러나 논문은 교차 검증 방식이나 테스트 셋의 분리 비율을 명시하지 않아 모델 일반화 가능성을 평가하기 어려운 점이 있다. 또한, 데이터셋이 특정 기간과 플랫폼에 국한돼 있어 최신 변종 악성코드에 대한 적용 가능성을 검증하지 못했다. 향후 연구에서는 다중 플랫폼 데이터와 동적 행동 특성을 결합하고, 딥러닝 기반 시퀀스 모델을 비교 대상으로 포함시켜야 할 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기