다중채널 강인 음성인식을 위한 LSTM 기반 적응형 빔포밍 네트워크
** 본 논문은 LSTM을 이용해 실시간으로 빔포밍 필터를 적응적으로 추정하고, 이를 깊은 LSTM 음향 모델과 공동 학습함으로써 CHiME‑3 데이터셋에서 기존 단일채널 시스템 대비 최대 7.97% 절대 WER 감소를 달성한 방법을 제시한다. **
저자: Zhong Meng, Shinji Watanabe, John R. Hershey
**
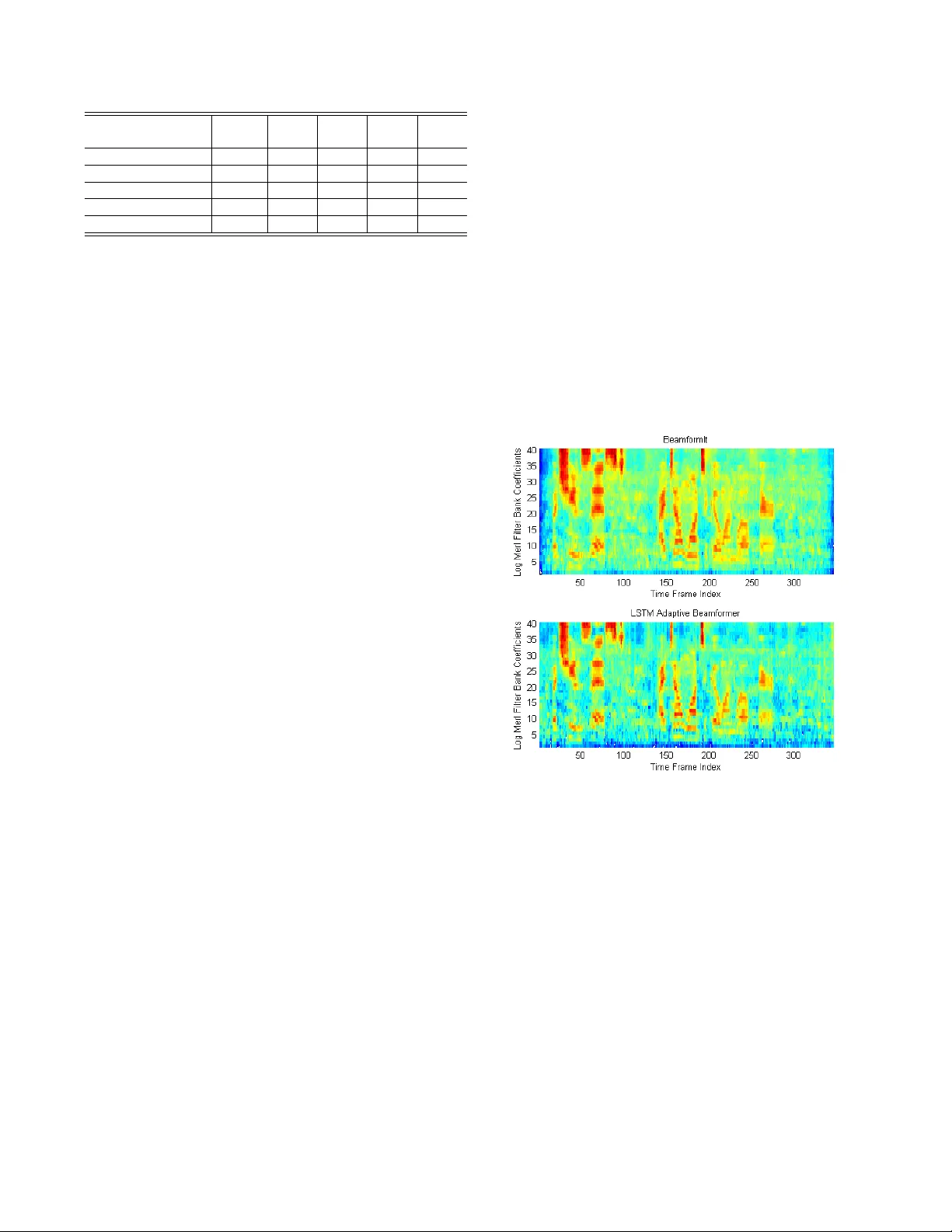
본 논문은 far‑field 환경에서의 음성 인식 성능 저하 문제를 해결하기 위해 다중 마이크 입력을 활용한 적응형 빔포밍과 깊은 LSTM 기반 음향 모델을 통합한 새로운 프레임워크를 제안한다. 기존의 고정 필터 기반 빔포밍(MVDR, GEV 등)은 신호‑레벨 최적화에 초점을 맞추어 환경 변화에 대한 적응성이 부족했다. 이를 보완하고자 저자들은 LSTM을 이용해 각 시간‑프레임마다 복소수 STFT 계수에 대한 필터‑앤‑섬 빔포밍 계수를 실시간으로 추정하는 적응형 빔포밍 네트워크를 설계하였다.
### 1. 적응형 LSTM 빔포밍 네트워크
- 입력: 5개의 마이크 채널(채널 1,3,4,5,6)에서 추출한 257 차원의 복소수 STFT(실수+허수) → 2 570 차원 실수 벡터.
- 전처리: 1 024 차원으로 선형 투사 후 단일 LSTM 층(1 024 유닛)으로 전달.
- 출력: 각 채널·주파수에 대한 실수·허수 필터 계수 gₜ,ₘ을 tanh 함수를 통해
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기