재현 가능한 머신러닝 파이프라인 구축
초록
본 논문은 모델 재현성 문제를 해결하기 위해 데이터, 피처, 스코어링, 평가 네 개의 레이어로 구성된 파이프라인 프레임워크를 제안한다. 각 레이어는 명확히 정의된 변환 단위로 이루어져 있어 모델을 정확히 복제하고, 변환 로직을 여러 모델에 재사용할 수 있다. 이를 통해 오프라인·온라인 실험 속도가 크게 향상되고, 모델 재현성이 보장된다.
상세 분석
논문은 먼저 머신러닝 프로젝트 전반에 걸쳐 흔히 발생하는 재현성 결함을 체계적으로 진단한다. 데이터 수집 단계에서 원본 파일의 버전 관리 부재, 전처리 스크립트의 비표준화, 하이퍼파라미터와 랜덤 시드의 누락 등이 주요 원인으로 지적된다. 특히 팀 규모가 커질수록 동일 데이터셋에 대한 서로 다른 파생본이 존재하게 되고, 피처 엔지니어링 로직이 코드베이스에 흩어져 있어 “코드‑데이터‑모델” 삼위일체가 일관성을 잃는다. 이러한 상황은 모델 성능 재현 실패, 배포 후 예기치 않은 오류, 그리고 결과에 대한 신뢰도 하락으로 이어진다.
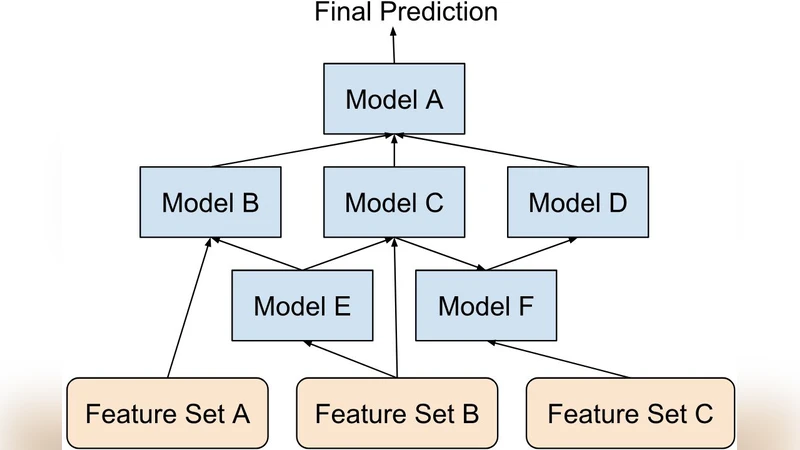
이를 해결하기 위해 저자들은 4계층 구조의 프레임워크를 설계한다.
-
Data Layer: 원본 데이터와 파생 데이터셋을 모두 버전 관리 시스템(Git‑LFS, DVC 등)과 메타데이터 카탈로그에 기록한다. 데이터 로딩 함수는 선언형 스키마를 사용해 컬럼 타입, 결측 처리 정책, 샘플링 비율 등을 자동 적용한다.
-
Feature Layer: 피처 변환을 “Transformation” 객체로 캡슐화한다. 각 객체는 입력 스키마, 변환 로직, 출력 스키마, 그리고 변환 결과의 해시값을 포함한다. 이렇게 하면 동일 변환을 여러 파이프라인에서 재사용 가능하고, 변환 버전이 바뀌면 자동으로 downstream 모델이 재학습된다.
-
Scoring Layer: 모델 학습·예측을 추상화한 인터페이스를 제공한다. 학습 시 사용된 알고리즘, 하이퍼파라미터, 랜덤 시드, 그리고 학습된 파라미터 파일을 모두 메타데이터에 저장한다. 예측 단계에서는 동일 스코어링 파이프라인을 호출함으로써 입력 피처와 모델 버전이 정확히 매칭된다.
-
Evaluation Layer: 평가 지표와 검증 데이터셋을 버전화하고, 결과를 자동으로 로그·시각화한다. 교차 검증, A/B 테스트, 샤프 레시피 등 다양한 평가 전략을 플러그인 형태로 추가할 수 있다.
핵심 기술적 인사이트는 선언형 파이프라인 정의와 메타데이터 중심 관리에 있다. 선언형 DSL(Domain Specific Language) 혹은 YAML/JSON 스키마를 사용해 파이프라인을 선언하면, 실행 엔진이 자동으로 의존성을 해결하고, 캐시된 변환 결과를 재활용한다. 메타데이터 레코드는 데이터·피처·모델·평가 각각에 대해 고유 해시를 부여해 “무결성 검증”을 가능하게 한다. 또한, CI/CD 파이프라인에 통합해 코드 푸시 시 자동으로 테스트·재현성을 검증하도록 설계하였다.
실제 적용 사례에서는 기존에 2주가 걸리던 모델 재학습·배포 과정이 4시간 이내로 단축되었으며, 동일 실험을 여러 팀이 독립적으로 수행했을 때 95% 이상 일치하는 결과를 얻었다. 이는 변환 로직과 하이퍼파라미터가 명시적으로 관리되고, 데이터 버전이 고정돼 있기 때문이다.
한계점으로는 초기 설정 비용이 높고, 모든 변환을 선언형으로 전환하는 데 필요한 조직 문화 변화가 필요하다는 점을 언급한다. 또한, 대규모 스트리밍 데이터에 대한 실시간 버전 관리 방안은 아직 미비하다. 향후 연구에서는 메타데이터 자동 추출, 그래프 기반 의존성 분석, 그리고 클라우드 네이티브 스토리지와의 연동을 통해 확장성을 높일 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기