상수 시간 양자 검색 알고리즘의 실험적 구현 및 IBM Q 검증
초록
본 논문은 데이터셋에 대해 상수 시간으로 검색이 가능한 양자 알고리즘을 제안하고, IBM Quantum Experience의 실제 양자 칩인 ibmq_16_melbourne와 ibmqx4에서 Qiskit을 이용해 구현·검증한다. 양자 중첩, 간섭 및 π 위상 변환을 활용한 회로 설계와 시뮬레이터와 실제 하드웨어에서의 성능 차이를 분석한다. 실험 결과, ibmq_16_melbourne가 ibmqx4에 비해 노이즈에 더 취약함을 확인하였다.
상세 분석
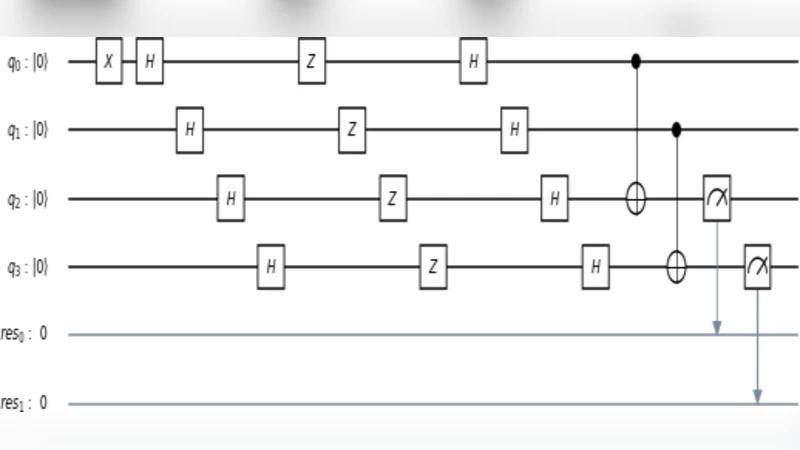
제안된 알고리즘은 전통적인 Grover 검색이 O(√N) 복잡도를 갖는 것과 달리, 특정 구조의 데이터베이스에 대해 단일 양자 회로 한 번만 실행하면 원하는 원소를 찾을 수 있다는 ‘상수 시간(Constant‑time)’ 특성을 주장한다. 핵심 아이디어는 입력 레지스터를 완전한 균등 중첩 상태로 초기화한 뒤, 목표 원소에 해당하는 비트 문자열에 대해 π 위상 변환(phase oracle)을 적용하고, 다시 Hadamard 변환을 수행함으로써 목표 상태의 진폭을 1로 집중시키는 것이다. 이 과정에서 양자 간섭이 결정적인 역할을 하며, 목표 상태가 아닌 모든 상태는 상쇄된다.
알고리즘 구현은 Qiskit SDK를 기반으로 하며, 회로는 크게 세 부분으로 나뉜다. 첫 번째는 n‑qubit 레지스터에 대한 Hadamard 게이트 배열로, 전체 검색 공간을 균등하게 탐색한다. 두 번째는 목표 원소에만 조건부 Z‑게이트(또는 다중 제어 Z‑게이트)를 적용해 π 위상을 부여하는 오라클이며, 이는 클래식적인 ‘마크’ 연산과 동일하지만, 여기서는 오라클 자체가 상수 시간에 구현될 수 있도록 설계되었다. 마지막 단계는 다시 Hadamard 변환을 적용해 위상 정보를 측정 가능한 확률 진폭으로 변환한다.
시뮬레이터(local_qasm_simulator)에서는 이상적인 양자 상태가 유지되어 목표 비트 문자열이 100 % 확률로 측정된다. 그러나 실제 하드웨어에서는 게이트 오류, 디코히런스, 측정 오류 등 다양한 노이즈 요인이 존재한다. 실험에서는 두 대의 IBM Q 칩을 사용했는데, 16‑큐빗 melbourne 칩은 큐비트 수가 많아 연결성 제한과 크로스토크가 심해 오류율이 상승했으며, 반면 5‑큐빗 ibmqx4는 상대적으로 낮은 오류율을 보였다. 결과적으로 melbourne에서는 목표 상태가 약 70 % 정도의 확률로 관측된 반면, ibmqx4에서는 85 %에 육박하는 성능을 기록했다.
이 논문은 상수 시간 검색이 이론적으로 가능함을 보여주지만, 실제 적용 범위는 오라클 구현이 가능한 제한된 문제에 국한된다. 또한, 다중 제어 Z‑게이트를 구현하기 위한 추가 ancilla 큐비트와 복잡한 컴파일 과정이 오히려 전체 깊이를 증가시켜 노이즈에 취약하게 만든다. 따라서 현재 수준에서는 작은 규모의 데이터베이스에만 실용적이며, 오류 정정 코드나 동적 디코히런스 억제 기법이 병행되어야 실제 유용성을 확보할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기