회의 중 겹침 음성 인식을 위한 다채널 분리 신경망 접근
초록
본 논문은 회의 환경에서 화자 겹침을 효과적으로 처리하기 위해 ‘언믹싱 트랜스듀서’를 제안한다. 다채널 마이크 입력을 고정된 두 개의 동기화된 출력 스트림으로 변환하고, 각 발화를 하나의 채널에 독립적으로 배치한다. 윈도우 기반 BLSTM과 퍼뮤테이션 인베리언트 트레이닝(PIT)을 이용해 스펙트럼 마스크와 잡음 마스크를 추정하며, 이를 기반으로 MVDR 빔포머를 적용한다. 실험 결과, 기존 신경망 마스크 기반 빔포머 대비 10.8%의 단어 오류율(WER) 개선을 달성했으며, 특히 겹침 구간에서 큰 향상을 보였다.
상세 분석
이 연구는 회의 녹음과 같이 화자 수와 발화 시점이 사전에 알려지지 않은 실환경에서의 겹침 음성 인식 문제를 해결하고자 한다. 핵심 아이디어는 ‘언믹싱 트랜스듀서(unmixing transducer)’라는 신호 처리 모듈을 도입해, 입력된 다채널 음성을 고정된 J개의 출력 스트림(논문에서는 J=2)으로 변환하는 것이다. 각 출력 스트림은 시간 동기화된 오디오 시퀀스로, 한 발화는 어느 한 채널에 완전하게 매핑되고, 겹침이 없을 경우 남는 채널은 제로 신호를 출력한다. 이를 위해 저자들은 다음과 같은 기술적 요소를 결합하였다.
-
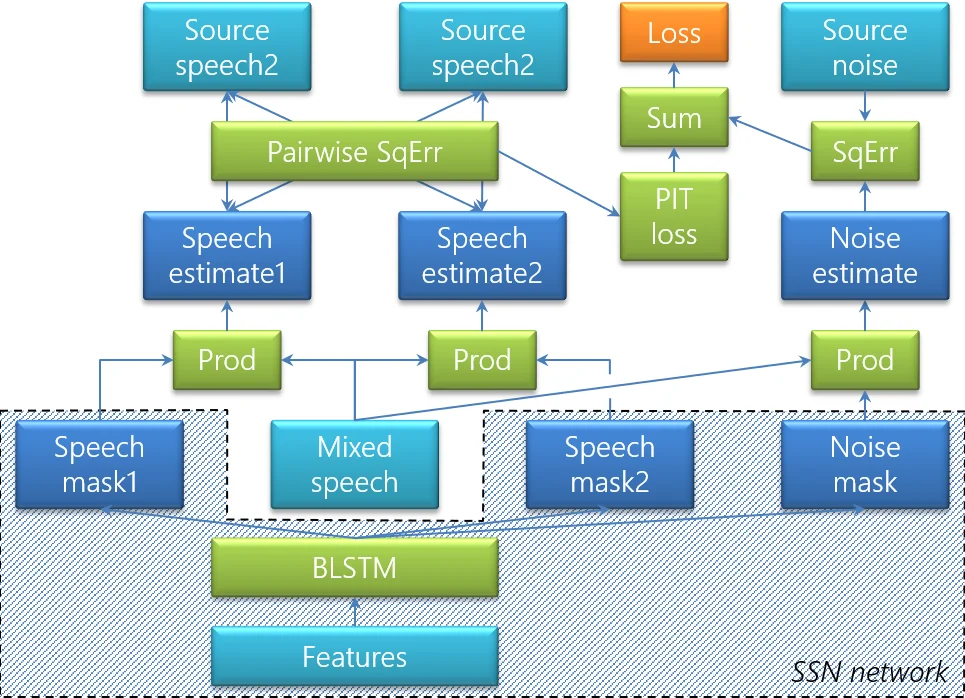
윈도우 기반 BLSTM: 회의는 수십 분에서 수시간에 이르는 장시간 신호이므로, 전체를 한 번에 처리하기 어렵다. 2.4초 길이의 슬라이딩 윈도우(75% 오버랩)를 사용해 각 구간을 독립적으로 처리하고, 인접 윈도우 간 마스크 순서를 정렬(stitching)함으로써 발화가 채널 간에 섞이는 현상을 방지한다. BLSTM은 시간적 종속성을 포착해 발화 경계와 스펙트럼 변화를 정확히 모델링한다.
-
입력 특징: 스펙트럼 특징으로는 기준 마이크의 magnitude spectrum을 사용하고, 공간 정보는 마이크 간 위상 차이(IPD)를 활용한다. IPD는 4초 롤링 평균을 이용해 평균 정규화한 뒤, π 경계 문제를 피하기 위해 Arg 연산을 적용한다.
-
퍼뮤테이션 인베리언트 트레이닝(PIT): 두 발화가 동시에 존재하는 경우, 네트워크가 출력 채널에 할당하는 순서를 사전에 정하지 않는다. PIT 손실을 최소화하는 순열을 학습 단계에서 자동으로 선택함으로써, 각 윈도우 내에서 일관된 채널 매핑을 보장한다.
-
마스크 기반 빔포머: 스펙트럼 마스크만으로는 ASR 성능에 잡음이 남을 수 있기 때문에, 추정된 마스크를 이용해 MVDR 빔포머를 구성한다. 목표 발화와 방해 발화(또는 잡음)의 공간 공분산 행렬을 각각 마스크 가중치와 1‑마스크 가중치로 추정한다. 기존 방법은 방해 공분산을 단순히 1‑마스크로 대체했지만, 본 논문은 ‘Speech‑Speech‑Noise(SSN)’ 모델을 도입해 잡음 전용 마스크를 별도로 학습, 방해 공분산을 ‘다른 화자 스피치 + 잡음’으로 분해한다. 이는 빔포머의 방해 억제 성능을 크게 향상시킨다.
-
학습 데이터와 구현: 567시간 분량의 합성 다채널 혼합 데이터를 구축했으며, WSJ와 LibriSpeech를 원본 음성으로 사용하고, 이미지 방법으로 방을 시뮬레이션해 리버베레이션을 적용했다. 잡음은 구면 등방성 잡음장을 가정해 추가하였다. 모델은 3‑layer 1024‑unit BLSTM에 1024‑unit ReLU 프리프로젝션을 두고, 최종 출력은 3‑head sigmoid 레이어(스피치1, 스피치2, 잡음)로 구성된다. 16 GPU에서 1‑bit SGD로 학습했으며, 검증 손실이 최소인 스냅샷을 선택한다.
-
실험 및 결과: 7채널 원형 마이크 어레이를 이용해 실제 회의 6개(30~60분)를 녹음하고, 전문 전사자를 통해 정답을 확보했다. 겹침 비율은 평균 14.7%로 기존 AMI 코퍼스보다 두 배 이상이었다. 언믹싱 트랜스듀서를 적용한 시스템은 기존 최첨단 신경망 마스크 기반 빔포머 대비 전체 WER에서 10.8% 개선을 보였으며, 겹침 구간에서는 더욱 큰 감소를 기록했다. 또한, 두 화자 이상이 동시에 말할 경우에도 추가 채널을 0‑signal으로 처리해 안정적인 동작을 유지한다.
핵심 기여는 (1) 실시간 회의 환경에 맞춘 고정 출력 채널 구조, (2) 윈도우 BLSTM과 PIT를 결합한 견고한 마스크 추정, (3) SSN 모델을 통한 정확한 방해 공분산 추정, (4) 실제 회의 데이터에서 입증된 성능 향상이다. 이 접근법은 회의 기록, 원격 협업, 의료 대화 등 다중 화자 환경에서의 자동 전사 시스템에 바로 적용 가능하며, 향후 화자 수가 더 많거나 동적 마이크 배열에 대한 확장 연구가 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기