온라인 독성 댓글 탐지를 위한 머신러닝 스위트
초록
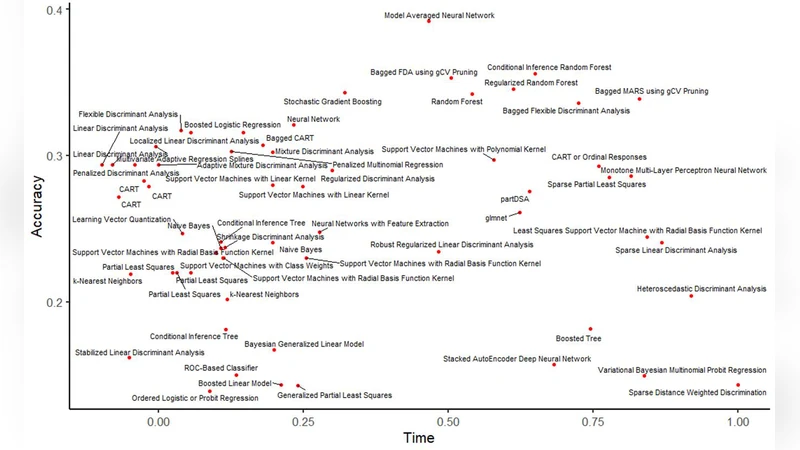
본 논문은 위키피디아 Jigsaw 데이터셋을 활용해 62개의 분류기(19개 알고리즘 군)를 평가하고, 정확도와 실행 시간을 비교한다. 트리 기반 모델이 가장 해석 가능하고, 28개의 특징 중 단순 욕설 리스트가 가장 강력한 예측력을 보인다.
상세 분석
이 연구는 온라인 커뮤니티에서 독성 발언을 자동으로 탐지하기 위한 전처리, 특징 추출, 모델 선택 과정을 체계적으로 검증한다. 먼저 원시 텍스트를 형태소 분석, n‑gram, 감성 사전, 감정 사전, 그리고 이상치 단어 사전 등 28개의 다차원 특징으로 변환한다. 이 중 욕설 사전 기반의 이진 피처가 가장 높은 변수 중요도를 보였으며, 이는 복잡한 감성·감정 점수보다 독성 판단에 직접적인 영향을 미친다는 점을 시사한다.
다음으로 62개의 분류기를 19개의 알고리즘 패밀리(예: 결정 트리, 랜덤 포레스트, 그래디언트 부스팅, 서포트 벡터 머신, 로지스틱 회귀, 신경망 등)로 구성해 교차 검증을 수행했다. 정확도 차이는 부트스트랩 기반의 통계 검정으로 유의성을 판단했으며, 실행 시간은 동일한 하드웨어 환경에서 평균 측정했다. 결과적으로 트리 기반 모델(특히 XGBoost와 랜덤 포레스트)이 높은 정확도와 비교적 짧은 학습·예측 시간을 동시에 만족시켰다. 반면 딥러닝 모델은 학습 비용이 크게 늘었지만 정확도 향상이 미미해 실용성 측면에서 불리했다.
해석 가능성 측면에서 트리 모델은 각 특징의 기여도를 순위화할 수 있어 정책 입안자나 운영자가 모델 결과를 신뢰하고 조정하기 용이했다. 또한, 모델 간 차이를 시각화한 히트맵과 ROC 곡선을 제공해 성능 비교를 직관적으로 제시했다. 최종적으로 저자는 “단순 욕설 리스트 + 트리 기반 모델” 조합이 비용 효율적이며 실시간 모니터링 시스템에 바로 적용 가능하다고 결론짓는다.
이 연구는 독성 탐지 분야에서 알고리즘 선택과 특징 설계가 서로 긴밀히 연결되어 있음을 강조한다. 특히, 복잡한 딥러닝보다 전통적인 머신러닝이 데이터 규모가 제한된 상황에서 더 나은 성능‑효율 균형을 제공한다는 점을 실증적으로 보여준다. 향후 연구에서는 다언어 데이터셋, 사용자 행동 메타데이터, 그리고 지속적인 모델 업데이트 메커니즘을 통합해 시스템의 일반화 능력을 강화할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기