노이즈 환경에서 화산 분출을 구분하는 머신러닝: 뉴멕시코 Chimayo 가스 분출 사례 연구
초록
본 연구는 뉴멕시코 Chimayo에 위치한 CO₂‑구동 냉수 간헐천의 지진 데이터를 고역통과 Butterworth 필터와 자기회귀(AR) 모델을 이용해 다단계로 잡음 제거한 뒤, 700여 개의 시계열 특징을 추출·선택하여 100여 개로 축소하고, 랜덤 포레스트(Random Forest) 분류기로 ‘잔여 잡음’, ‘전조’, ‘분출’ 세 상태를 구분한다. 완전 필터링된 데이터에서 90 % 이상의 정확도를 달성했으며, 동적 시간 정렬(DTW)과 부분 필터링된 경우에 비해 성능이 크게 향상됨을 보였다.
상세 분석
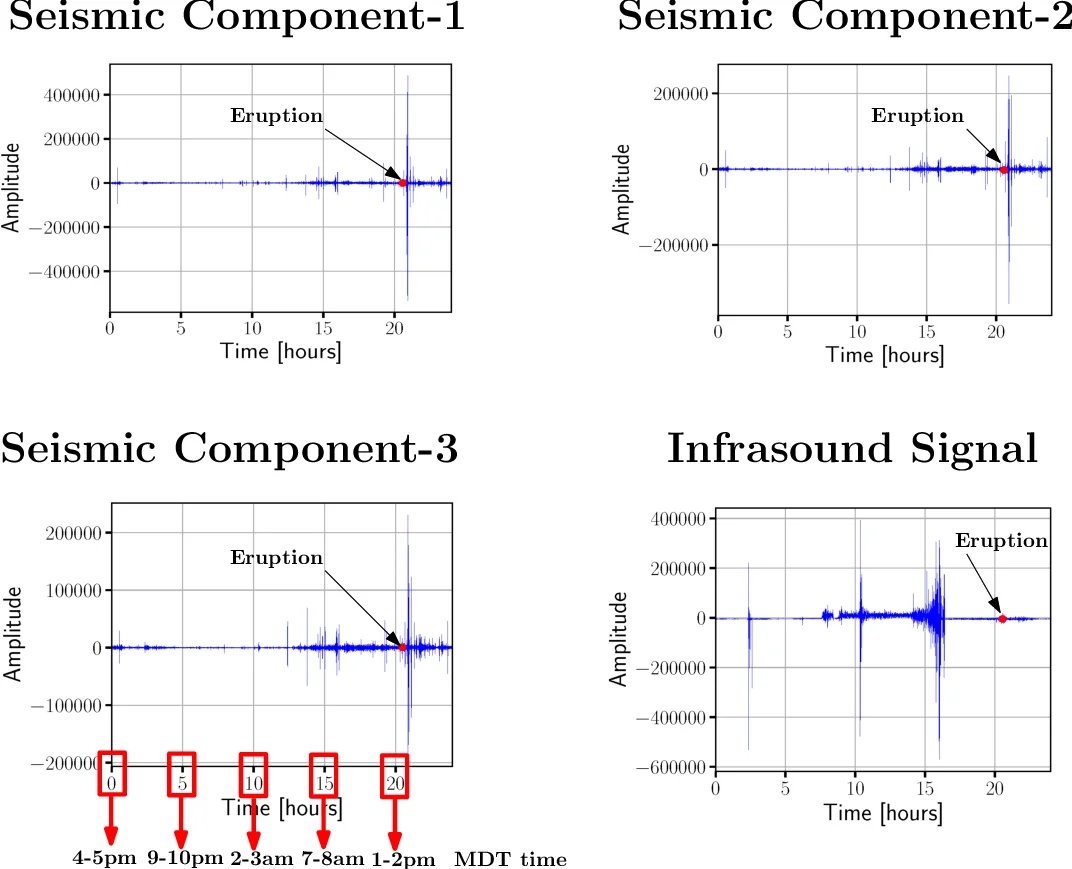
이 논문은 지하 CO₂ 누출을 모니터링하기 위한 자연 아날로그인 Chimayo 간헐천을 대상으로, 고도로 잡음이 섞인 지진 신호에서 유의미한 이벤트를 추출하는 방법론을 제시한다. 데이터는 200 Hz로 샘플링된 18일간의 연속 기록(학습 14일, 테스트 4일)이며, 현장에 설치된 모션 센서로 분출 시점을 라벨링한다. 주요 난점은 일일·계절 온도 변동, 인간·동물 활동 등 다양한 비정상 잡음이 신호에 크게 섞여 있다는 점이다. 이를 해결하기 위해 두 단계의 전처리를 적용한다. 첫 번째 단계는 Butterworth 고역통과 필터를 이용해 저주파 계절·일주기 성분을 제거한다. 두 번째 단계는 AR(p) 모델을 학습해 잡음의 예측값을 구하고, 원 신호에서 이를 차감하는 예측오차필터(Prediction Error Filter)를 적용한다. AR 차수 p는 AIC 기준으로 자동 선택하며, 전체 데이터의 5 %만을 잡음 전용 학습에 사용해 전조·분출 신호를 보존한다.
전처리 후에는 1분(12 000 샘플) 길이의 슬라이딩 윈도우를 설정하고, tsfresh 라이브러리를 활용해 700여 개의 통계·주파수·시계열 특성을 추출한다. 이후 상관·분산 분석 등 통계적 중요도 검정을 통해 약 100개의 핵심 특징을 선정하고, 그 중 상위 10개는 부분 자기상관, FFT 계수, 스펙트럼 중심, 왜도·첨도 등이다. 이렇게 차원 축소된 특징 벡터를 입력으로 랜덤 포레스트 분류기를 학습한다. 랜덤 포레스트는 부트스트랩 샘플링과 무작위 특성 선택을 통해 개별 결정트리의 과적합을 억제하고, 다중 클래스(잔여 잡음, 전조, 분출) 구분에 높은 강인성을 보인다.
실험 결과, 완전 필터링된 데이터에 대해 랜덤 포레스트는 90 % 이상의 정확도를 기록했으며, 부분 필터링(계절 트렌드만 제거)에서는 87 %로 약간 감소했다. 반면 동적 시간 정렬(DTW) 기반 분류는 44 %에 머물렀다. 이는 잡음 억제와 비선형 특징 추출이 결합될 때 머신러닝 모델의 성능이 크게 향상된다는 점을 입증한다. 또한 모델의 추론 시간은 약 10⁻⁴ 초 수준으로 실시간 모니터링에 충분히 적용 가능함을 보여준다.
이 연구는 CO₂ 저장소에서 발생할 수 있는 누출을 조기에 탐지하기 위한 신호 처리·머신러닝 파이프라인을 제시한다는 점에서 의의가 크다. 특히, 잡음이 심한 현장 데이터에서도 전조 신호를 구분할 수 있다는 점은 기존의 단순 임계값 기반 감시 체계보다 훨씬 높은 신뢰성을 제공한다. 다만, 연구는 단일 현장(Chimayo)와 제한된 기간(18일)만을 대상으로 했으며, 다른 지질·환경 조건에서의 일반화 가능성은 추가 검증이 필요하다. 향후 연구에서는 다중 센서 융합, 딥러닝 기반 자동 특징 학습, 그리고 실제 CO₂ 누출 실험 데이터와의 비교를 통해 모델의 범용성을 확대할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기