시스템 개발자를 위한 개인정보 위험 측정 모델
초록
본 논문은 사용자가 데이터 제공 시 인지하는 개인정보 위험을 정량화할 수 있는 모델을 제안한다. 데이터 민감도·가시성·응용 프로그램과의 연관성을 변수로 삼아 위험 점수를 산출하고, 151명의 설문 응답을 통해 모델의 타당성을 검증하였다. 결과는 가시성이 위험 인식에 가장 큰 영향을 미친다는 점을 강조한다.
상세 분석
이 연구는 개인정보 보호 설계 단계에서 개발자가 사용자 관점의 위험을 계량적으로 파악하도록 돕는 실용적인 프레임워크를 제공한다는 점에서 의미가 크다. 모델은 세 가지 핵심 차원을 기반으로 한다. 첫째, **데이터 민감도(Sensitivity)**는 정보 자체가 갖는 잠재적 피해 규모를 나타내며, 기존 문헌에서 제시된 민감도 등급(예: 식별 가능성, 재식별 위험 등)을 정량화한다. 둘째, **데이터 가시성(Visibility)**는 사용자가 입력한 정보가 애플리케이션 내에서 얼마나 노출되는지를 측정한다. 여기에는 기본 UI 표시 여부, 로그 저장, 제3자 공유 여부 등이 포함된다. 셋째, **데이터 연관성(Relevance)**은 해당 데이터가 서비스 제공에 필수적인지를 평가한다; 높은 연관성은 사용자가 위험을 감수할 의향을 높이는 요인으로 작용한다.
모델은 이 세 변수를 곱셈 형태로 결합해 Perceived Privacy Risk (PPR) = α·Sensitivity × β·Visibility ÷ γ·Relevance와 같은 형태의 점수를 산출한다. 여기서 α, β, γ는 설문 데이터를 기반으로 회귀 분석을 통해 추정된 가중치이며, β가 가장 큰 값을 차지함을 확인했다. 이는 사용자가 직접 눈으로 확인할 수 있는 가시성이 위험 인식에 결정적 영향을 미친다는 기존 연구와 일치한다.
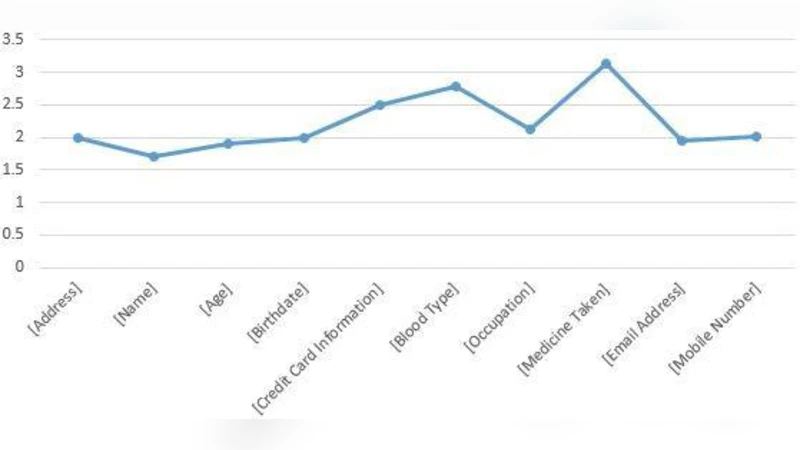
실증 조사에서는 151명의 일반 사용자에게 12개의 가상의 데이터 항목(예: 이름, 위치, 건강 기록 등)을 제시하고, 각 항목에 대해 위험 인식을 7점 Likert 척도로 평가하도록 했다. 설문 설계는 전통적 위험 요인(민감도, 가시성, 연관성) 외에도 **사용자 인구통계(연령, 성별, IT 활용도)**를 통제 변수로 포함하였다. 수집된 데이터는 다중 회귀 분석과 구조 방정식 모델(SEM)로 검증했으며, 모델 적합도 지표(CFI=0.96, RMSEA=0.04)는 충분히 높은 편이었다.
하지만 몇 가지 한계도 존재한다. 첫째, 설문에 사용된 데이터 항목은 가상의 시나리오에 기반했으며, 실제 서비스 환경에서의 복합적인 데이터 흐름을 완전히 재현하지 못한다. 둘째, 참여자 표본이 주로 대학생 및 직장인에 국한돼 있어 연령·문화적 다양성을 충분히 반영하지 못한다. 셋째, 가시성 변수는 UI 디자인 요소에 크게 의존하는데, 이는 플랫폼(모바일 vs 웹)마다 차이가 날 수 있다. 이러한 점을 보완하기 위해 향후 실제 서비스 로그와 연계한 실시간 위험 측정 및 다문화 사용자 테스트가 필요하다.
전반적으로 이 논문은 개인정보 위험을 정량화하려는 시도에서 가시성을 핵심 요인으로 강조함으로써, 개발자가 UI/UX 설계 단계에서 위험 최소화를 위한 구체적 가이드라인을 도출할 수 있게 한다는 점에서 실무적 가치를 제공한다. 또한, 모델이 비교적 간단한 수식으로 구현 가능하다는 점은 다양한 개발 환경에 손쉽게 적용될 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기