SAIL 머신러닝 기반 구조 분석 공격으로 하드웨어 난독화 해제
초록
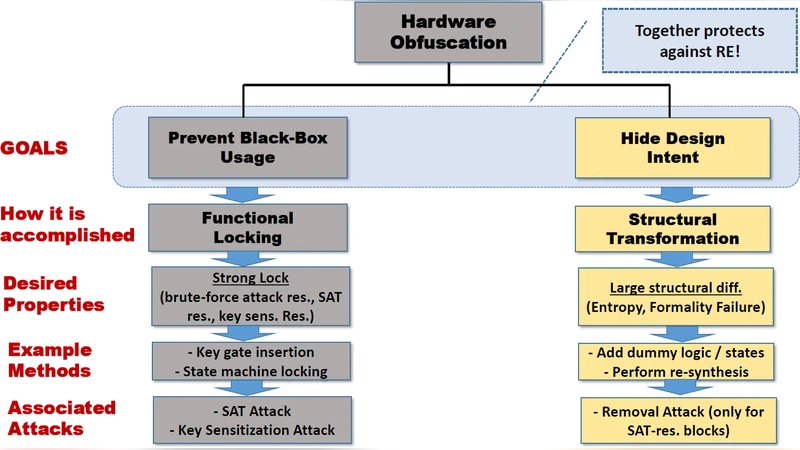
본 논문은 기존 논리 난독화 기법이 회로 구조에 미치는 변화가 국소적이고 규칙적이라는 사실을 이용해, 머신러닝 모델로 이러한 변화를 예측·복원함으로써 설계 의도를 추출하는 새로운 구조 공격인 SAIL을 제안한다. SAT 기반 기능 공격과 달리 금형(골든) 회로가 필요 없으며, 84 % 이상(최대 95 %)의 변형을 복원해내는 높은 정확도를 보인다.
상세 분석
SAIL은 하드웨어 난독화의 구조적 약점을 공략한다는 점에서 기존 연구와 차별화된다. 논문은 먼저 XOR‑기반 키 게이트 삽입 후 재합성(synthesis) 과정에서 발생하는 구조 변화를 ‘Level‑1(변화 없음)’, ‘Level‑2(인접 게이트 변형)’, ‘Level‑3(키 게이트 자체와 주변 회로 변형)’으로 구분하고, 실험을 통해 전체 로컬리티 중 약 36 %는 Level‑1, 57 %는 Level‑2, 나머지 6 %만이 실제 난독화 효과를 가진다고 밝혔다. 중요한 점은 재합성 도구가 사용하는 변환 규칙이 매우 제한적이라는 사실이다. 전체 변환 중 90 % 이상이 180개의 규칙 안에 포함되고, 상위 6개의 규칙만으로도 41 %를 설명한다는 통계는 머신러닝이 충분히 학습 가능함을 시사한다.
이를 기반으로 두 개의 ML 모델을 설계한다. 첫 번째는 Random Forest 기반 ‘변화 예측 모델’로, 주어진 로컬 서브그래프가 재합성 후 변형되었는지를 10‑gate 규모까지 81 % 이상의 정확도로 판단한다. 두 번째는 다층 신경망 기반 ‘재구성 모델’로, 변형된 포스트‑합성 로컬리티를 입력받아 사전‑합성 형태를 복원한다. 모델은 로컬리티 크기에 따라 여러 개를 학습하고, 누적 신뢰 투표(ensemble) 방식을 적용해 복원 정확도를 높인다.
학습 데이터는 ‘Pseudo Self‑Referencing’ 기법을 사용한다. 공격자는 이미 난독화된 회로를 임시 골든 회로로 삼아 한 번 더 동일한 난독화 과정을 적용해 학습용(전‑후 로컬리티 쌍) 데이터를 생성한다. 이렇게 하면 원본 설계에 접근하지 않아도 회로‑특화된 변환 패턴을 충분히 확보할 수 있다.
실험은 ISCAS‑85 벤치마크 7개에 대해 8‑64 bit 키를 삽입한 다양한 시나리오에서 수행되었다. 전체 평균 복원율은 84.14 %이며, 가장 큰 회로(c7552)에서는 94.98 %에 달한다. 특히 구조가 규칙적인 회로에서는 98 % 이상의 변형 예측 정확도를 기록한다. 이러한 결과는 기존 SAT 기반 공격이 필요로 하는 ‘언락된 IC’가 없더라도, 구조적 정보를 통해 설계 의도를 효과적으로 추출할 수 있음을 입증한다.
SAIL의 장점은 (1) 기능적 응답이 필요 없고, (2) 순차·조합 회로 모두 적용 가능하며, (3) 특정 논리 함수(예: 곱셈기)에 취약한 SAT 공격과 달리 모든 회로에 일반화 가능하고, (4) 키 길이·벤치마크 규모에 따라 정확도와 실행 시간이 선형적으로 확장된다는 점이다. 다만, 현재는 XOR‑기반 단순 키 게이트 삽입에 초점을 맞추었으며, 보다 복잡한 구조 변형(예: 라우팅 레벨 난독화)에는 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기