다중기관 연합 AI 구축 방안
초록
정부 내 서로 다른 규제와 데이터 공유 제한을 극복하기 위해 연합 학습(Federated AI)을 적용한 연구이다. 데이터는 현장에 남겨두고 모델 파라미터만 교환함으로써 각 기관의 보안 요구를 만족하면서도 공동 모델을 학습한다. 실험 결과는 전통적인 중앙집중식 학습과 비슷한 성능을 보이며, 정책적·기술적 시사점을 제시한다.
상세 분석
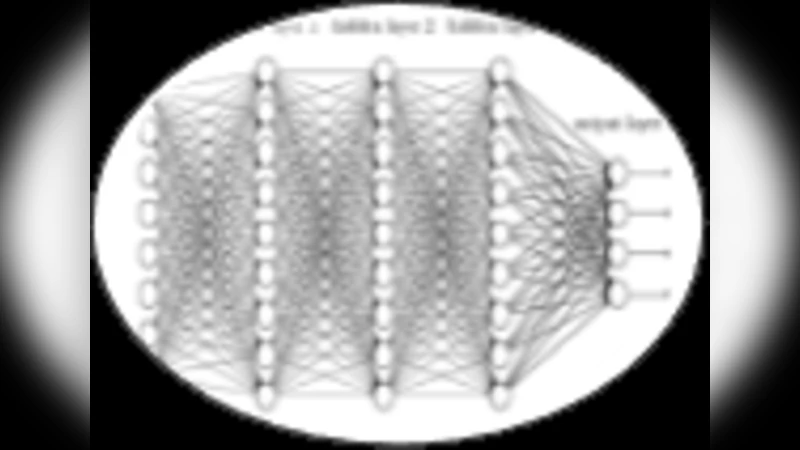
본 논문은 정부 기관 간 데이터 이동이 법적·규제적 장벽에 부딪히는 현실을 출발점으로 삼는다. 기존의 중앙집중식 AI 개발 방식은 데이터 소유권, 개인정보 보호법, 국가 안보 규정 등 다양한 제약에 의해 적용이 어려워졌다. 이를 해결하기 위해 연합 학습(Federated Learning, FL)이라는 분산 학습 패러다임을 도입했으며, 구체적으로는 다음과 같은 기술적 요소들을 검토한다. 첫째, 모델 파라미터와 그라디언트만을 교환하는 구조를 채택함으로써 원본 데이터는 각 기관 내부에 머무른다. 둘째, 통신 효율성을 높이기 위해 압축 및 양자화 기법을 적용하고, 비동기식 업데이트를 통해 네트워크 지연에 강인한 학습을 구현한다. 셋째, 보안 강화를 위해 차등 개인정보 보호(Differential Privacy)와 안전한 다자간 계산(Secure Multi‑Party Computation) 기법을 결합한다. 논문은 또한 연합 학습 과정에서 발생할 수 있는 데이터 불균형, 모델 편향, 그리고 악의적 참여자(Byzantine attacks) 문제를 다루며, 이를 완화하기 위한 가중치 조정 및 이상 탐지 메커니즘을 제시한다. 실험에서는 의료 기록, 교통 데이터, 재난 관리 데이터 등 서로 다른 도메인의 공개 데이터셋을 활용해 시뮬레이션을 수행했으며, 각 기관별 로컬 모델과 중앙집중식 모델의 성능 차이를 정량적으로 비교한다. 결과는 연합 모델이 평균 2~3% 수준의 정확도 손실만을 보이며, 데이터 이동 없이도 실용적인 수준의 AI 솔루션을 제공함을 증명한다. 마지막으로 정책적 관점에서 연합 AI 도입을 위한 가이드라인을 제시하고, 법적·조직적 협업 체계 구축의 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기