제한된 데이터에서도 뛰어난 음성 변환을 위한 오류 감소 네트워크
본 논문은 다중 화자 데이터를 이용해 평균 DBLSTM 모델을 사전 학습하고, 소량의 목표 화자 데이터로 적응(adaptation)한 뒤, 변환된 스펙트럼에 오류 감소 네트워크를 추가함으로써 제한된 병렬 데이터 환경에서도 기존 DBLSTM 기반 음성 변환보다 높은 품질과 화자 유사성을 달성하는 방법을 제안한다.
저자: Mingyang Zhang, Berrak Sisman, Sai Sirisha Rallab
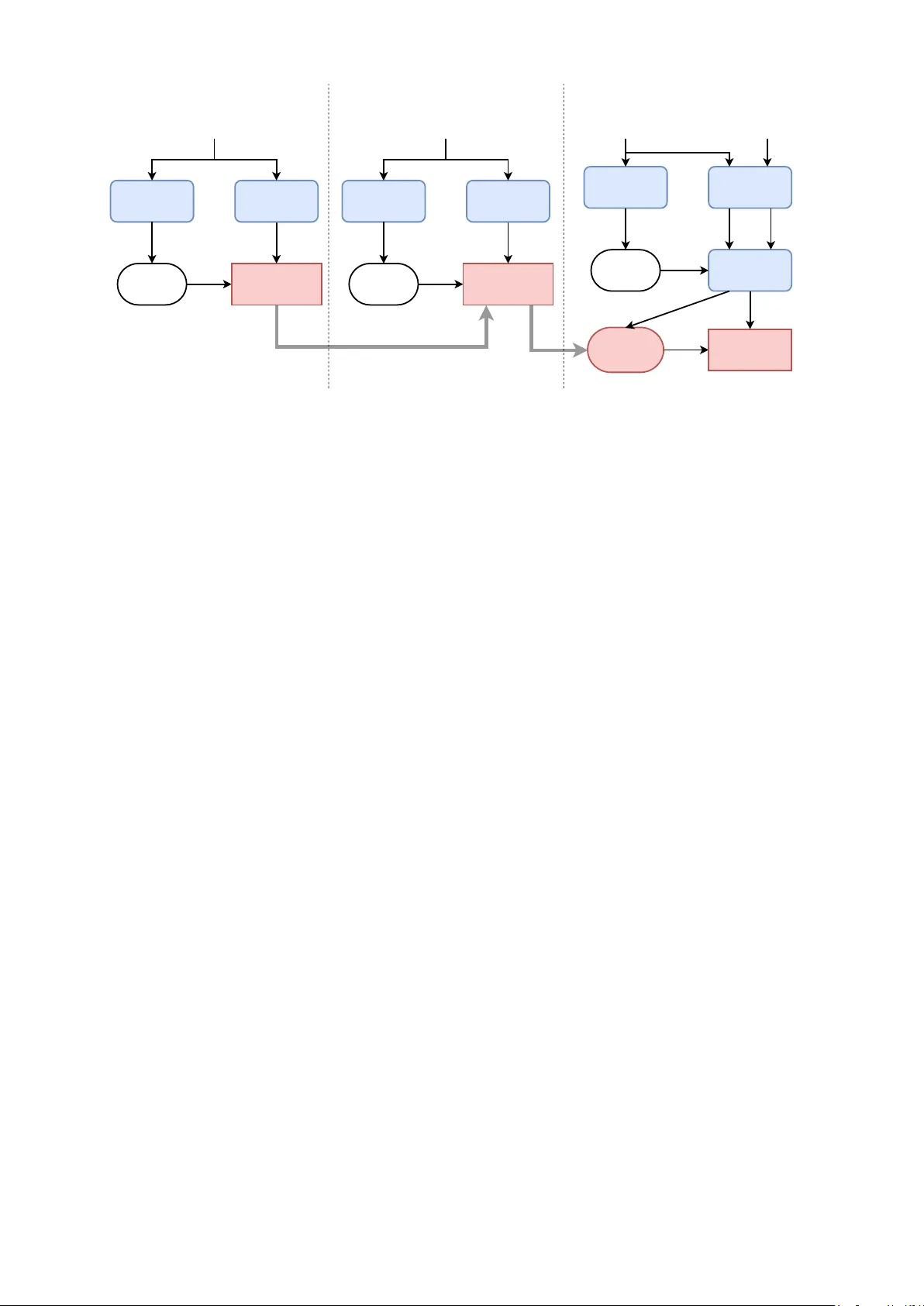
본 논문은 제한된 병렬 데이터 환경에서도 높은 품질의 음성 변환을 실현하기 위해, Deep Bidirectional Long Short-Term Memory(DBLSTM) 기반의 세 단계 학습 파이프라인을 제안한다. 첫 번째 단계에서는 다수 화자의 음성 데이터를 이용해 평균 모델을 사전 학습한다. 이때, 사전 훈련된 ASR 시스템으로부터 추출한 1‑hot 음소 레이블을 입력으로 사용하고, DBLSTM이 해당 레이블을 멜 켑스트럼 계수(MCEPs)와 매핑하도록 학습한다. 양방향 LSTM 구조는 앞뒤 컨텍스트를 동시에 고려해 장기 의존성을 효과적으로 포착함으로써, 기존 DNN 기반 프레임 단위 변환보다 스펙트럼 변환 정확도가 높다.
두 번째 단계에서는 목표 화자(target speaker)의 소량 데이터만을 사용해 평균 모델을 적응(adapt)한다. 논문에서는 목표 화자(slt)의 45문장을 학습에 활용했으며, 이 과정은 평균 모델의 파라미터를 초기값으로 그대로 유지하고 목표 화자 데이터에 대해 추가 학습하는 방식이다. 병렬 데이터가 필요 없다는 점에서 실용성이 크게 향상된다. 적응 후 모델은 목표 화자의 스펙트럼 특성을 보다 정확히 반영하지만, 여전히 변환된 MCEPs와 실제 목표 MCEPs 사이에 미세한 차이가 존재한다.
이를 보완하기 위해 세 번째 단계에서는 오류 감소 네트워크(Error Reduction Network)를 도입한다. 이 네트워크 역시 DBLSTM 구조를 사용하지만, 입력으로 변환된 MCEPs의 전·후 프레임을 포함한 3‑프레임 윈도우를 사용해 시간적 맥락을 강화한다. 학습에는 적응 단계와 동일한 문장을 소스와 목표 화자 양쪽에서 수집한 병렬 데이터(50문장)를 활용한다. 오류 감소 네트워크는 변환된 MCEPs와 목표 MCEPs 사이의 잔여 오류를 정밀하게 보정함으로써, 최종 출력 스펙트럼을 목표 스펙트럼에 가깝게 만든다.
실험은 CMU ARCTIC 코퍼스를 이용해 남성→여성 교차 성별 변환을 수행하였다. 실험 설정은 다음과 같다. (1) 베이스라인: 기존 DBLSTM 기반 병렬 학습 모델, 100문장의 병렬 데이터 사용. (2) 평균 모델 적응만 수행한 모델: 목표 화자 45문장으로 적응, 병렬 데이터 없음. (3) 제안된 전체 파이프라인: 평균 모델 → 적응 → 오류 감소 네트워크, 병렬 데이터 50문장 사용.
객관적 평가지표인 멜 켑스트럼 왜곡(MCD) 결과는 9.32 dB(소스), 6.30 dB(베이스라인), 6.20 dB(제안 모델)로, 제안 모델이 가장 낮은 왜곡을 기록했다. 주관적 평가에서는 MOS 테스트와 ABX 선호도 테스트를 수행했으며, MOS 점수는 베이스라인 2.62, 평균 모델 적응 2.71, 제안 모델 3.41로 제안 모델이 가장 높은 자연스러움과 화자 유사성을 얻었다. ABX 테스트에서도 제안 모델이 베이스라인보다 현저히 높은 선호도를 보였다.
이러한 결과는 (i) 다수 화자 데이터를 활용한 평균 모델이 강력한 사전 지식을 제공하고, (ii) 소량 목표 화자 데이터만으로도 효과적인 모델 적응이 가능함을, (iii) 오류 감소 네트워크가 잔여 오류를 정밀히 보정해 전체 시스템 성능을 크게 향상시킨다는 세 가지 핵심 인사이트를 입증한다. 특히, 제한된 병렬 데이터(50문장)만으로도 100문장 병렬 데이터 기반 베이스라인을 능가하는 성능을 달성했으며, 데이터 효율성 측면에서 큰 의미를 가진다.
향후 연구 방향으로는 비병렬 상황에서도 적용 가능한 자동 정렬 및 음소 인식 기법, F0와 포먼트와 같은 추가 음성 특성에 대한 오류 감소 네트워크 확장, 그리고 실시간 변환을 위한 경량화 모델 설계 등이 제시된다. 본 논문의 접근법은 음성 변환뿐 아니라 화자 변환, 감정 변환 등 다양한 음성 스타일 변환 작업에 일반화될 가능성을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기