인간처럼 소프트웨어를 테스트하는 머신
초록
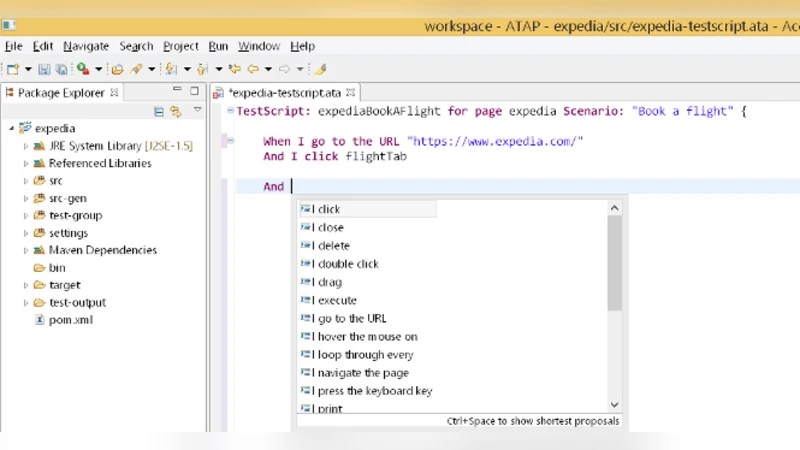
본 논문은 테스트 스크립트를 자연어에 가깝게 작성하고, 컴퓨터 비전 기반 객체 인식을 통해 GUI 요소를 자동으로 찾아 행동을 수행함으로써, 구현 세부 정보에 의존하지 않는 인간형 테스트 자동화 프레임워크를 제안한다.
상세 분석
이 연구는 기존 Selenium·Sikuli와 같은 자동화 도구가 HTML ID·XPath 등 구현 세부에 의존해 스크립트 생성·유지보수가 어렵다는 문제점을 정확히 짚어낸다. 해결책으로 제시된 DSL(Domain Specific Language)은 제한된 자연어 구문을 사용해 테스트 스텝을 기술하도록 설계됐으며, 파싱 단계에서 ‘동작’과 ‘대상 요소’를 명확히 분리한다. 요소 식별은 두 단계로 이루어진다. 첫째, 실행 시점에 화면 캡처를 수행하고 OCR을 적용해 화면상의 텍스트를 추출한다. 둘째, 추출된 텍스트와 DSL에서 명시된 라벨을 입력으로 CNN‑LSTM 모델에 전달해 해당 라벨이 시각적으로 나타나는 좌표(x, y)를 예측한다. 이때 CNN은 이미지 특징을, LSTM은 텍스트‑시각 관계를 학습해 라벨‑위치 매핑을 수행한다. 모델은 약 2 200개의 수동 라벨링 데이터를 이용해 사전 학습했으며, 실험 결과 ‘중간 정도’의 정확도를 보였지만, 데이터 규모 확대와 전이 학습을 통해 향상이 기대된다. 좌표가 확보되면 Java Robot 클래스로 마우스·키보드 이벤트를 발생시켜 클릭·텍스트 입력·드롭다운 선택 등을 수행한다.
주요 장점은(1) 구현 세부에 대한 의존성을 완전히 배제해 스크립트 유지보수가 GUI 레이아웃 변화에 강인함, (2) 웹·데스크톱·모바일 등 다양한 UI 플랫폼에 동일한 DSL을 적용할 수 있는 범용성, (3) 라벨 간 시각적 관계(예: ‘Title’ 라벨 옆의 드롭다운)를 활용해 인간이 인식하는 방식과 일치하는 테스트 로직을 작성할 수 있다는 점이다. 반면 한계로는 OCR 오류, 라벨이 이미지에 명시되지 않은 경우(아이콘·이미지‑버튼) 식별 실패 가능성, 현재 지원 요소가 버튼·텍스트박스·링크·드롭다운에 국한된 점을 들 수 있다. 또한, 실시간 화면 변화에 대한 대응 속도가 Selenium에 비해 느릴 수 있으며, 대규모 애플리케이션에 적용하려면 모델 재학습 및 데이터 라벨링 비용이 발생한다.
전반적으로 이 논문은 ‘자연어‑시각 인식’이라는 새로운 패러다임을 제시함으로써 테스트 자동화의 진입 장벽을 낮추고, 유지보수 비용을 크게 절감할 잠재력을 보여준다. 향후 연구에서는 멀티‑모달 학습, 더 풍부한 UI 요소 지원, 그리고 CI/CD 파이프라인과의 연동을 통해 실용성을 강화할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기