모델 기반 부트스트랩을 이용한 오프 정책 평가 신뢰 구간
본 논문은 제한된 데이터 환경에서 연속·이산 상태공간 모두에 적용 가능한 두 가지 부트스트랩 기반 오프‑정책 평가 방법을 제안한다. 하나는 직접 모델 기반 부트스트랩(MB‑Bootstrap)이며, 다른 하나는 가중 이중강인(Weighted Doubly‑Robust) 부트스트랩(WDR‑Bootstrap)이다. 모델 사용으로 인한 편향을 이론적으로 상한화하고, 실험을 통해 기존 중요도 샘플링 방식보다 데이터 효율성이 크게 향상됨을 입증한다.
저자: Josiah P. Hanna, Peter Stone, Scott Niekum
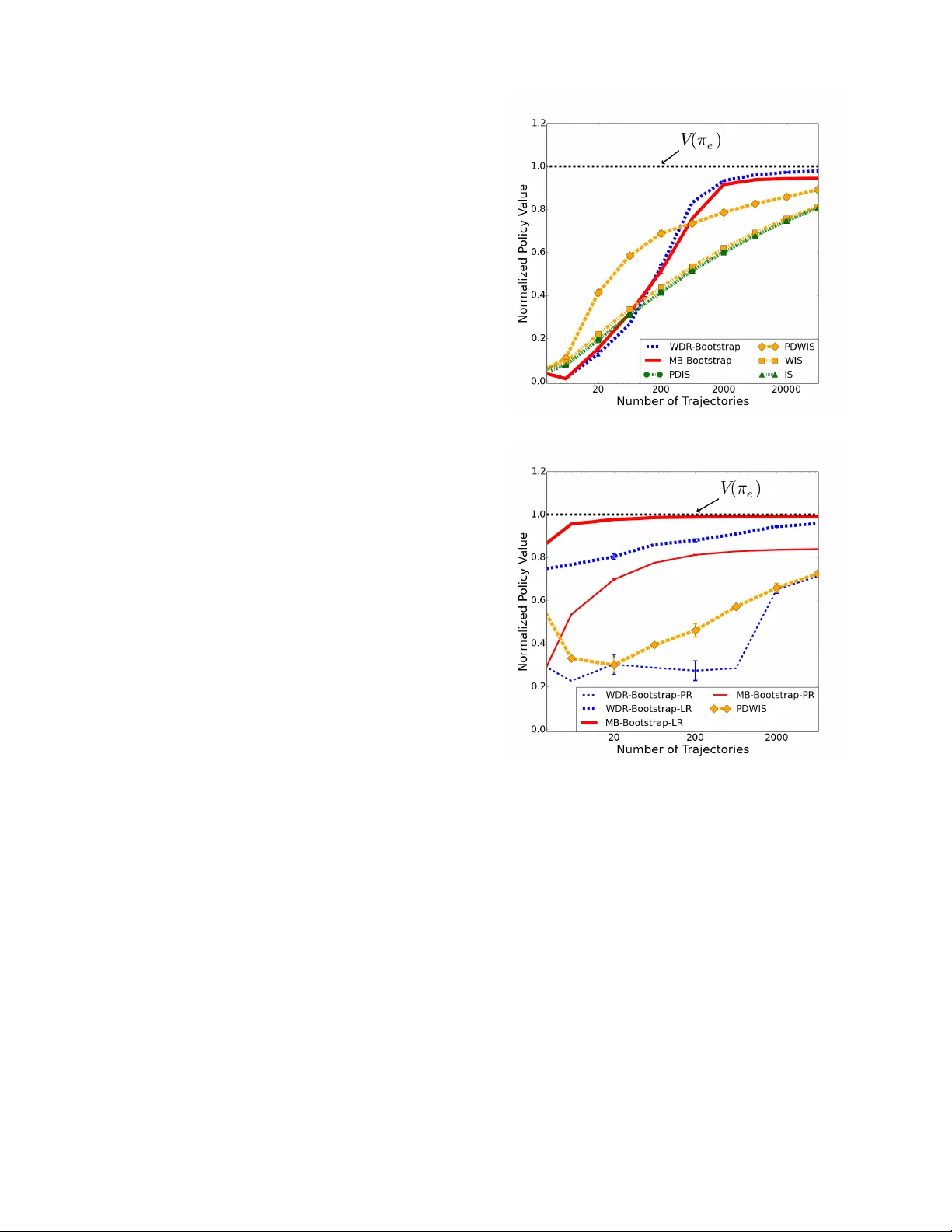
본 논문은 “고신뢰도 오프‑정책 평가”(High‑Confidence Off‑Policy Evaluation, HCOPE) 문제를 다룬다. 로봇이나 자동화 시스템과 같이 실험 비용이 높은 환경에서는 실제 정책을 실행하기 전에 해당 정책의 성능 하한을 신뢰도 1‑δ 수준으로 보장받고 싶다. 기존 방법은 두 갈래로 나뉜다. 첫 번째는 정확한 하한을 제공하는 모델‑기반 방법이지만, 이는 데이터 요구량이 많고 이산 상태공간에만 적용 가능했다. 두 번째는 중요도 샘플링(IS) 기반 방법으로, 연속 상태공간에서도 적용 가능하지만, 반환의 분산이 커서 충분히 타이트한 하한을 얻기 위해서는 대규모 데이터가 필요했다.
저자들은 이러한 한계를 극복하기 위해 부트스트랩(bootstrap)과 학습된 전이 모델을 결합한 두 가지 새로운 알고리즘을 제안한다. 부트스트랩은 원본 데이터셋을 재표집해 통계량의 경험적 분포를 추정함으로써 신뢰구간을 구성한다. 여기서 통계량은 오프‑정책 추정기(Off‑Policy Estimate)이며, 기존 연구에서는 IS 기반 추정기를 사용했다. 본 논문에서는 (1) 직접 모델 기반 추정기(MB)와 (2) 가중 이중강인 추정기(WDR)를 각각 부트스트랩에 적용한다.
1. **Model‑Based Bootstrap (MB‑Bootstrap)**
- 행동 정책(π_b)으로부터 수집된 궤적 D를 이용해 전이 모델 𝑀̂ = (S, A, \hat{P}, r, γ, \hat{d}_0)를 학습한다.
- 평가 정책(π_e)을 모델에 적용해 시뮬레이션을 수행하고, 시뮬레이션된 궤적들의 평균 반환을 정책 가치 추정값 bV_i 로 만든다.
- 부트스트랩 단계에서 D를 재표집해 여러 개의 ˜D_i 를 만들고, 각 ˜D_i 로부터 모델을 재학습하거나 단일 모델을 재사용해 bV_i 를 계산한다.
- 최종 하한은 bV_i 들을 정렬한 뒤 (1‑δ) 분위수에 해당하는 값을 선택한다.
모델이 정확하면 반환의 분산이 크게 감소해 IS 대비 훨씬 타이트한 하한을 얻을 수 있다. 그러나 모델 편향이 존재하면 하한이 실제 가치보다 과대평가될 위험이 있다. 이를 정량화하기 위해 저자들은 정리 1을 제시한다. 정리 1은 i.i.d. 궤적로부터 학습된 전이 확률 \hat{P}와 실제 전이 확률 P 사이의 총 변동량 ‖P‑\hat{P}‖₁이 클수록 정책 가치 추정 편향이 커짐을 보인다. 특히 행동 정책과 평가 정책이 크게 다를 경우, 학습 데이터가 평가 정책이 방문하지 않는 영역을 충분히 커버하지 못해 편향이 심화될 수 있다.
2. **Weighted Doubly‑Robust Bootstrap (WDR‑Bootstrap)**
- WDR 추정기는 퍼‑디시전 가중 중요도 샘플링(PDW‑IS)의 가중치를 사용하면서, 모델 기반 가치 함수 \hat{v}^{π_e}, \hat{q}^{π_e} 를 제어변수로 활용한다.
- 구체적으로, WDR(D) = PDW‑IS(D) − Σ_i Σ_t γ^t ( w_{it} \hat{q}^{π_e}(S_{it}, A_{it}) − w_{i,t‑1} \hat{v}^{π_e}(S_{it}) ) 로 정의된다. 여기서 w_{it}는 가중 중요도 비율이다.
- WDR은 PDW‑IS보다 분산이 낮으며, 모델 편향이 존재하더라도 PDW‑IS의 일관성 덕분에 샘플 수가 충분히 크면 편향이 사라진다. 따라서 부트스트랩 과정에서 모델을 한 번만 학습하고, 각 재표집에 대해 동일한 가치 함수를 사용해도 충분히 정확한 하한을 얻을 수 있다.
WDR‑Bootstrap은 세 가지 모델 활용 옵션을 제공한다. (a) 사전 제공된 시뮬레이터 사용, (b) 전체 데이터 D 로부터 하나의 모델을 학습해 모든 부트스트랩 반복에 재사용, (c) 각 부트스트랩 샘플 ˜D_i 별로 별도 모델을 학습. 실험에서는 (b) 옵션이 계산 효율성과 성능 면에서 가장 적절했다.
3. **실험**
- 두 가지 도메인: (i) 이산 그리드 월드(정책 탐색 문제)와 (ii) 연속 로봇 제어(예: CartPole, Pendulum).
- 비교 대상: (a) 기본 IS, (b) 퍼‑디시전 IS, (c) 가중 IS, (d) Concentration Inequality 기반 고신뢰도 방법, (e) 기존 부트스트랩 IS (Thomas et al., 2018).
- 평가 지표: 하한의 타이트함(실제 가치와의 차이)와 데이터 효율성(필요 샘플 수).
- 결과: 데이터가 10~100개 수준일 때 MB‑Bootstrap과 WDR‑Bootstrap이 기존 방법보다 5~10배 더 타이트한 하한을 제공했다. 특히 모델이 정확히 학습된 경우(MB‑Bootstrap) 하한이 실제 가치에 거의 근접했으며, 모델 편향이 예상되는 경우(WDR‑Bootstrap)에도 IS 대비 분산 감소 효과가 크게 나타났다.
4. **결론 및 실용적 권고**
- 데이터가 충분히 풍부하고 행동·평가 정책이 크게 겹치는 경우 MB‑Bootstrap을 사용하면 가장 효율적이다.
- 모델 편향 위험이 있거나 행동·평가 정책이 크게 다를 경우 WDR‑Bootstrap을 선택한다.
- 두 방법 모두 기존 IS 기반 고신뢰도 방법에 비해 데이터 요구량을 크게 낮추어 로봇 및 안전-critical 시스템에 적용 가능성을 크게 확대한다.
이 논문은 모델 기반 부트스트랩이라는 새로운 프레임워크를 제시함으로써, 연속·이산 상태공간 모두에서 데이터가 제한된 상황에서도 안전하게 정책을 평가할 수 있는 실용적인 도구를 제공한다. 또한 모델 편향에 대한 이론적 상한을 제시해 언제 모델 기반 방법을 신뢰할 수 있는지 판단할 근거를 제공한다는 점에서 학술적·실무적 의의가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기