음성 인식용 학습 기반 음소 거리 메트릭
초록
본 논문은 인간의 음소 인지 데이터를 이용해 기존 이론적 거리 함수보다 정확한 음소 유사도 메트릭을 자동으로 학습하는 프레임워크를 제시한다. 영어와 히브리어의 혼동 행렬을 통해 학습된 메트릭이 기존의 특징 기반 거리보다 예측력이 뛰어나며, 학습된 가중치를 통해 각 음성학적 특징의 지각적 중요도(살리언시)를 정량화한다.
상세 분석
이 연구는 두 가지 핵심 가정을 바탕으로 한다. 첫째, 음소는 미리 정의된 특징 공간(예: 유성/무성, 조음 위치, 조음 방식 등)에 벡터로 표현될 수 있다는 전제이다. 둘째, 인간 청자들이 실제로 경험하는 혼동 확률은 이 특징 공간에서의 거리와 일정한 함수 관계에 놓여 있다고 본다. 논문은 이러한 관계를 선형 변환(양의 대각 행렬) 형태의 메트릭으로 모델링하고, 실제 혼동 행렬을 최소제곱 손실 함수에 넣어 최적의 가중치를 학습한다.
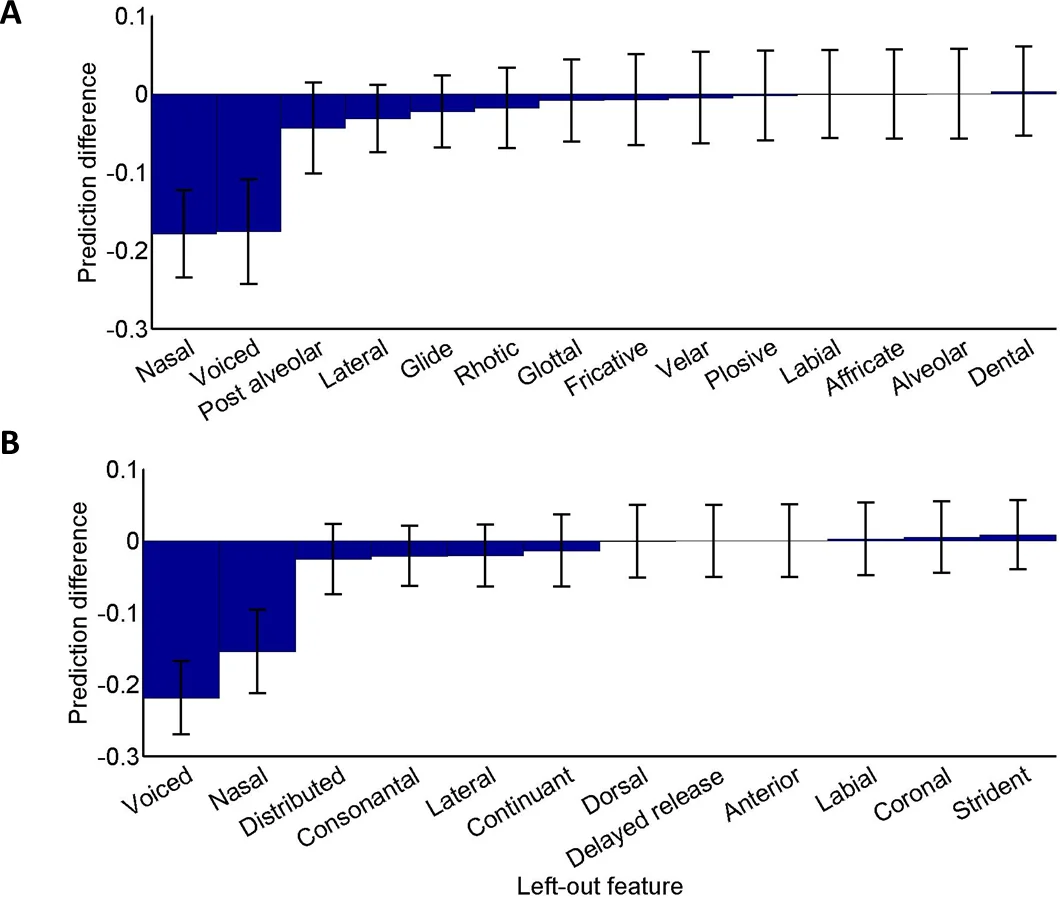
학습 과정은 크게 세 단계로 나뉜다. (1) 기존 음소 특징 체계에 따라 각 음소를 𝑁‑차원 이진 벡터로 코딩한다. (2) 인간 청자들의 실험적 혼동 데이터(확률 행렬)를 거리 형태로 변환한다(예: 𝑑_ij = √(−log P(i→j)) 등). (3) 특징 벡터 사이의 유클리드 거리와 변환된 실험 거리 사이의 차이를 최소화하도록 대각 가중치 w_k를 학습한다. 가중치가 클수록 해당 특징이 지각적으로 더 민감함을 의미한다.
실험에서는 Miller‑Nicely(1955)와 Luce(1987)의 두 영어 데이터셋, 그리고 새로 수집한 히브리어 데이터셋을 사용했다. 모든 경우에서 학습된 메트릭은 기존의 “공통 특징 수” 방식, “자연 클래스 비율” 방식, 그리고 “가중치 부여된 특징 수” 방식보다 높은 상관계수(R²)와 낮은 RMSE를 기록했다. 특히 영어에서는 /t/‑/f/와 같은 비대칭 혼동을 잘 포착했으며, 히브리어에서는 /b/‑/v/와 같이 언어별 특수성을 반영하는 가중치 차이가 관찰되었다.
이러한 결과는 두 가지 중요한 이론적 함의를 가진다. 첫째, 전통적인 특징 기반 이론이 가정하는 등가 가중치가 실제 지각과는 차이가 있음을 실증한다. 둘째, 언어마다 특징의 지각적 살리언시가 다를 수 있음을 보여주어, 보편적 특징 이론에 대한 재검토를 촉구한다.
비판적으로는 몇 가지 제한점이 있다. (1) 현재 모델은 대각 행렬만을 허용하므로 특징 간 상호작용을 반영하지 못한다. (2) 실험 데이터가 주로 초기 자음에 국한돼 있어 모음이나 종결 자음에 대한 일반화가 미흡하다. (3) 혼동 행렬을 거리로 변환하는 방법이 임의적이며, 다른 변환 방식에 따라 결과가 달라질 가능성이 있다. 향후 연구에서는 비선형 변환, 특징 간 상관관계 모델링, 그리고 다양한 언어와 소음 조건을 포함한 대규모 데이터셋을 활용해 메트릭을 확장할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기