소형 키워드 인식의 성능을 끌어올린 딥 레지듀얼 네트워크
초록
**
본 논문은 구글 Speech Commands 데이터셋을 기준으로 딥 레지듀얼 학습과 팽창(다이레이트) 합성곱을 적용한 키워드 스포팅 모델을 제안한다. 6개의 레지듀얼 블록으로 구성된 res15 모델은 기존 구글 CNN(91.7 % 정확도)을 크게 앞서 95.8 % 정확도를 달성했으며, 모델 깊이·폭을 조절해 파라미터 수와 연산량을 크게 줄인 소형 모델도 경쟁 모델들을 능가한다.
**
상세 분석
**
이 연구는 작은 메모리와 낮은 연산량을 요구하는 모바일·IoT 환경에서의 키워드 스포팅 문제에 초점을 맞추었다. 기존 연구들은 주로 CNN 기반의 경량화 모델을 제시했으며, 최근에는 RNN이나 CRNN을 도입해 장기 의존성을 학습하려는 시도가 있었다. 그러나 RNN 계열은 구현 복잡도와 실시간 추론 비용이 높아 실제 디바이스에 적용하기 어려운 점이 있다.
논문은 이러한 한계를 극복하기 위해 두 가지 핵심 기술을 도입한다. 첫째, ResNet 구조를 차용해 “잔차 학습”을 적용함으로써 네트워크가 깊어져도 학습이 안정적으로 진행되도록 했다. 레지듀얼 블록은 입력을 그대로 다음 블록에 더해 주는 skip connection을 사용해 기울기 소실 문제를 완화하고, 동일한 깊이의 순수 CNN보다 더 높은 표현력을 확보한다. 둘째, 다이레이트 합성곱(dilated convolution)을 이용해 필터의 수용 영역을 기하급수적으로 확대했다. 이는 입력 1초 길이의 MFCC 시퀀스를 적은 층수만으로 전체 시간‑주파수 맥락을 포착하게 해 주며, RNN이 제공하는 장기 의존성 모델링 효과를 CNN 내부에서 구현한다는 점에서 의미가 크다.
구조적 세부사항을 살펴보면, 기본 모델인 res15은 6개의 레지듀얼 블록과 45개의 채널을 사용한다. 각 블록은 bias‑free 3×3 합성곱 → BatchNorm → ReLU 순서로 구성되며, 블록 사이에 다이레이트 파라미터 (dw, dh)를 1, 2, 4, … 로 증가시키는 exponential schedule을 적용한다. 이 설계는 최종 수용 영역을 125×125로 확장해 1초 전체를 한 번에 처리한다.
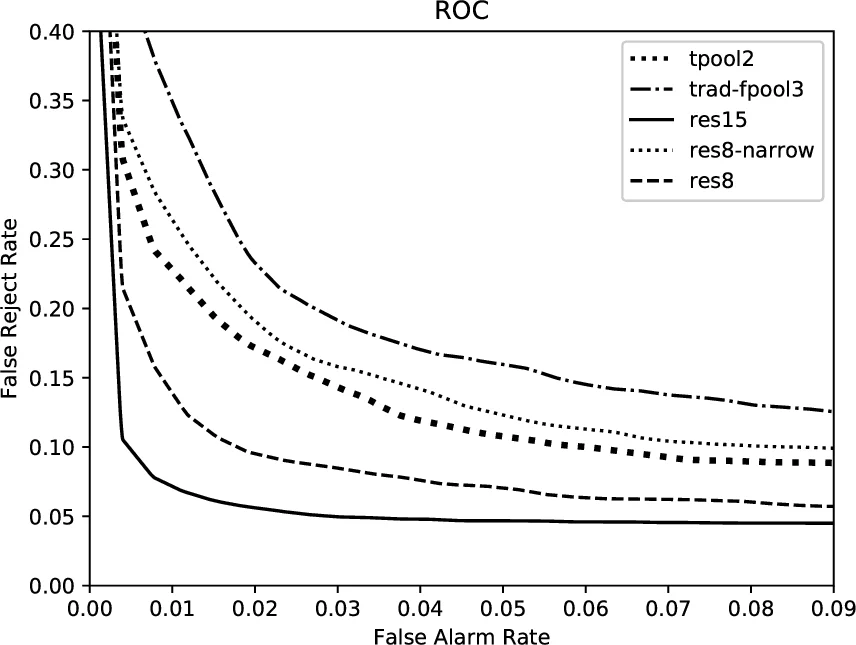
파라미터와 연산량 측면에서 res15는 238 K 파라미터와 894 M multiply‑accumulate 연산을 요구한다. 이는 기존 Google CNN(tpool2, 1.09 M 파라미터, 103 M 연산)보다 파라미터는 적지만 연산량은 많다. 따라서 메모리 제한이 심한 디바이스보다는 연산량이 비교적 풍부한 환경에서 최적이다.
소형 모델을 위해 저자들은 res8(깊이 절반)과 res8‑narrow(채널 19) 등을 설계했다. res8‑narrow은 파라미터 19.9 K, 연산 5.65 M으로 기존 one‑stride1 모델(12 K 파라미터, 5.76 M 연산)보다 파라미터는 비슷하지만 정확도는 90.1 %로 크게 앞선다. 특히 res8(폭 넓은 버전)은 110 K 파라미터와 30 M 연산으로 tpool2보다 정확도가 94.1 %로 높으며, 파라미터와 연산 모두 50배·18배 정도 절감한다.
깊이를 더 늘린 res26(12개의 레지듀얼 블록)에서는 오히려 정확도가 95.2 %로 약간 감소했으며, 이는 네트워크가 과도하게 깊어 최적화가 어려워졌음을 시사한다. 실험 결과는 “폭(채널 수)이 깊이보다 정확도에 더 큰 영향을 미친다”는 결론을 뒷받침한다.
학습 프로토콜은 원 논문의 설정을 그대로 따랐으며, SGD(모멘텀 0.9, 초기 학습률 0.1)와 L2 정규화(1e‑5)를 사용해 26 epoch(≈9 k 스텝) 동안 진행했다. 데이터 증강으로는 배경 잡음 삽입(확률 0.8)과 ±100 ms 시간 이동을 적용했으며, 전처리된 MFCC는 40 차원, 30 ms 윈도우, 10 ms 스트라이드로 1초 구간을 2D 텐서로 변환했다.
성능 평가는 정확도와 ROC‑AUC를 사용했으며, 5회 독립 실험(시드 변동)에서 95 % 신뢰구간을 제시했다. 모든 ResNet 변형이 기존 Google CNN을 통계적으로 유의하게 앞섰으며, 특히 소형 모델(res8‑narrow)은 파라미터와 연산량에서 극단적인 경량화를 달성하면서도 실용적인 정확도를 유지한다.
결론적으로, 이 논문은 딥 레지듀얼 학습과 다이레이트 합성곱이 키워드 스포팅이라는 제한된 자원 환경에서도 강력한 성능 향상을 제공한다는 것을 실증한다. 향후 연구에서는 공개된 RNN 기반 구현과의 직접 비교, 양자화·프루닝 등 추가 경량화 기법 적용, 그리고 실시간 모바일 디바이스에서의 벤치마크를 진행할 필요가 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기